B Memory Model Supplemental Material
This appendix contains non-normative documentation that helps explain the rationale behind and the workings of the RISC-V memory consistency models, including formal models of RVWMO.
B.1 RVWMO Explanatory Material
This section provides more explanation for RVWMO Section 3.1, using more informal language and concrete examples. These are intended to clarify the meaning and intent of the axioms and preserved program order rules. This appendix should be treated as commentary; all normative material is provided in Section 3.1 and in the rest of the main body of the ISA specification. All currently known discrepancies are listed in Section B.1.7. Any other discrepancies are unintentional.
B.1.1 Why RVWMO?
Memory consistency models fall along a loose spectrum from weak to strong. Weak memory models allow more hardware implementation flexibility and deliver arguably better performance, performance per watt, power, scalability, and hardware verification overheads than strong models, at the expense of a more complex programming model. Strong models provide simpler programming models, but at the cost of imposing more restrictions on the kinds of (non-speculative) hardware optimizations that can be performed in the pipeline and in the memory system, and in turn imposing some cost in terms of power, area overhead, and verification burden.
RISC-V has chosen the RVWMO memory model, a variant of release consistency. This places it in between the two extremes of the memory model spectrum. The RVWMO memory model enables architects to build simple implementations, aggressive implementations, implementations embedded deeply inside a much larger system and subject to complex memory system interactions, or any number of other possibilities, all while simultaneously being strong enough to support programming language memory models at high performance.
To facilitate the porting of code from other architectures, some hardware implementations may choose to implement the Ztso extension, which provides stricter RVTSO ordering semantics by default. Code written for RVWMO is automatically and inherently compatible with RVTSO, but code written assuming RVTSO is not guaranteed to run correctly on RVWMO implementations. In fact, most RVWMO implementations will (and should) simply refuse to run RVTSO-only binaries. Each implementation must therefore choose whether to prioritize compatibility with RVTSO code (e.g., to facilitate porting from x86) or whether to instead prioritize compatibility with other RISC-V cores implementing RVWMO.
Some fences and/or memory ordering annotations in code written for RVWMO may become redundant under RVTSO; the cost that the default of RVWMO imposes on Ztso implementations is the incremental overhead of fetching those fences (e.g., FENCE R,RW and FENCE RW,W) which become no-ops on that implementation. However, these fences must remain present in the code if compatibility with non-Ztso implementations is desired.
B.1.2 Litmus Tests
The explanations in this chapter make use of litmus tests, or small
programs designed to test or highlight one particular aspect of a memory
model. Litmus sample shows an example
of a litmus test with two harts. As a convention for this figure and for
all figures that follow in this chapter, we assume that s0-s2 are
pre-set to the same value in all harts and that s0 holds the address
labeled x, s1 holds y, and s2 holds z, where x, y, and z
are disjoint memory locations aligned to 8 byte boundaries. All other registers and all referenced memory locations are presumed to be initialized to zero. Each figure
shows the litmus test code on the left, and a visualization of one
particular valid or invalid execution on the right.
Table 67. A sample litmus test and one forbidden execution (a0=1).
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| ⋮ | ⋮ | ||
| li t1,1 | li t4,4 | ||
| (a) | sw t1,0(s0) | (e) | sw t4,0(s0) |
| ⋮ | ⋮ | ||
| li t2,2 | |||
| (b) | sw t2,0(s0) | ||
| ⋮ | ⋮ | ||
| (c) | lw a0,0(s0) | ||
| ⋮ | ⋮ | ||
| li t3,3 | li t5,5 | ||
| (d) | sw t3,0(s0) | (f) | sw t5,0(s0) |
| ⋮ | ⋮ | ||
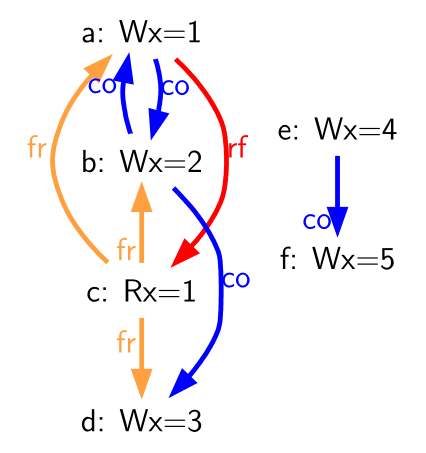
Litmus tests are used to understand the implications of the memory model
in specific concrete situations. For example, in the litmus test of
Litmus sample, the final value of a0
in the first hart can be either 2, 4, or 5, depending on the dynamic
interleaving of the instruction stream from each hart at runtime.
However, in this example, the final value of a0 in Hart 0 will never
be 1 or 3; intuitively, the value 1 will no longer be visible at the
time the load executes, and the value 3 will not yet be visible by the
time the load executes. We analyze this test and many others below.
Table 68. A key for the litmus test diagrams drawn in this appendix
| Edge | Full Name (and explanation) |
|---|---|
| rf | Reads From (from each store to the loads that return a value written by that store) |
| co | Coherence (a total order on the stores to each address) |
| fr | From-Reads (from each load to co-successors of the store from which the load returned a value) |
| ppo | Preserved Program Order |
| fence | Orderings enforced by a FENCE instruction |
| addr | Address Dependency |
| ctrl | Control Dependency |
| data | Data Dependency |
The diagram shown to the right of each litmus test shows a visual representation of the particular execution candidate being considered. These diagrams use a notation that is common in the memory model literature for constraining the set of possible global memory orders that could produce the execution in question. It is also the basis for the herd models presented in Section B.2.2. This notation is explained in Table 68. Of the listed relations, rf edges between harts, co edges, fr edges, and ppo edges directly constrain the global memory order (as do fence, addr, data, and some ctrl edges, via ppo). Other edges (such as intra-hart rf edges) are informative but do not constrain the global memory order.
For example, in Litmus sample, a0=1
could occur only if one of the following were true:
- (b) appears before (a) in global memory order (and in the
coherence order co). However, this violates RVWMO PPO
rule
ppo:→st. The co edge from (b) to (a) highlights this contradiction. - (a) appears before (b) in global memory order (and in the coherence order co). However, in this case, the Load Value Axiom would be violated, because (a) is not the latest matching store prior to (c) in program order. The fr edge from (c) to (b) highlights this contradiction.
Since neither of these scenarios satisfies the RVWMO axioms, the outcome
a0=1 is forbidden.
Beyond what is described in this appendix, a suite of more than seven thousand litmus tests is available at https://github.com/litmus-tests/litmus-tests-riscv.
The litmus tests repository also provides instructions on how to run the litmus tests on RISC-V hardware and how to compare the results with the operational and axiomatic models.
In the future, we expect to adapt these memory model litmus tests for use as part of the RISC-V compliance test suite as well.
B.1.3 Explaining the RVWMO Rules
In this section, we provide explanation and examples for all of the RVWMO rules and axioms.
B.1.3.1 Preserved Program Order and Global Memory Order
Preserved program order represents the subset of program order that must be respected within the global memory order. Conceptually, events from the same hart that are ordered by preserved program order must appear in that order from the perspective of other harts and/or observers. Events from the same hart that are not ordered by preserved program order, on the other hand, may appear reordered from the perspective of other harts and/or observers.
Informally, the global memory order represents the order in which loads and stores perform. The formal memory model literature has moved away from specifications built around the concept of performing, but the idea is still useful for building up informal intuition. A load is said to have performed when its return value is determined. A store is said to have performed not when it has executed inside the pipeline, but rather only when its value has been propagated to globally visible memory. In this sense, the global memory order also represents the contribution of the coherence protocol and/or the rest of the memory system to interleave the (possibly reordered) memory accesses being issued by each hart into a single total order agreed upon by all harts.
The order in which loads perform does not always directly correspond to the relative age of the values those two loads return. In particular, a load b may perform before another load a to the same address (i.e., b may execute before a, and b may appear before a in the global memory order), but a may nevertheless return an older value than b. This discrepancy captures (among other things) the reordering effects of buffering placed between the core and memory. For example, b may have returned a value from a store in the store buffer, while a may have ignored that younger store and read an older value from memory instead. To account for this, at the time each load performs, the value it returns is determined by the load value axiom, not just strictly by determining the most recent store to the same address in the global memory order, as described below.
B.1.3.2 Load value axiom
Section 3.1.1.4.1: Each byte of each load i returns the value written to that byte by the store that is the latest in global memory order among the following stores:
- Stores that write that byte and that precede i in the global memory order
- Stores that write that byte and that precede i in program order
Preserved program order is not required to respect the ordering of a store followed by a load to an overlapping address. This complexity arises due to the ubiquity of store buffers in nearly all implementations. Informally, the load may perform (return a value) by forwarding from the store while the store is still in the store buffer, and hence before the store itself performs (writes back to globally visible memory). Any other hart will therefore observe the load as performing before the store.
Consider the Table 69. When running this program on an implementation with
store buffers, it is possible to arrive at the final outcome a0=1, a1=0, a2=1, a3=0 as follows:
Table 69. A store buffer forwarding litmus test (outcome permitted)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | li t1, 1 | ||
| (a) sw t1,0(s0) | (e) sw t1,0(s1) | ||
| (b) lw a0,0(s0) | (f) lw a2,0(s1) | ||
| (c) fence r,r | (g) fence r,r | ||
| (d) lw a1,0(s1) | (h) lw a3,0(s0) | ||
Outcome: a0=1, a1=0, a2=1, a3=0 | |||
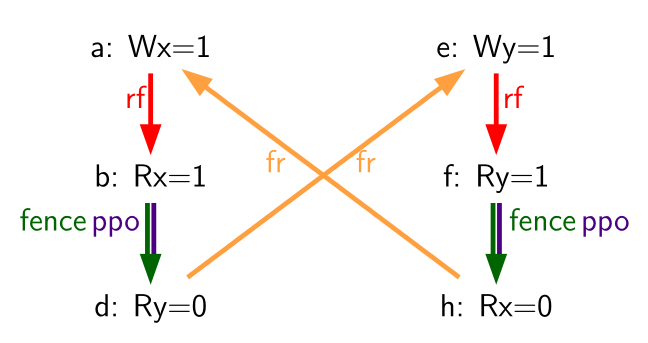
- (a) executes and enters the first hart’s private store buffer
- (b) executes and forwards its return value 1 from (a) in the store buffer
- (c) executes since all previous loads (i.e., (b)) have completed
- (d) executes and reads the value 0 from memory
- (e) executes and enters the second hart’s private store buffer
- (f) executes and forwards its return value 1 from (e) in the store buffer
- (g) executes since all previous loads (i.e., (f)) have completed
- (h) executes and reads the value 0 from memory
- (a) drains from the first hart’s store buffer to memory
- (e) drains from the second hart’s store buffer to memory
Therefore, the memory model must be able to account for this behavior.
To put it another way, suppose the definition of preserved program order did include the following hypothetical rule: memory access a precedes memory access b in preserved program order (and hence also in the global memory order) if a precedes b in program order and a and b are accesses to the same memory location, a is a write, and b is a read. Call this Rule X. Then we get the following:
- (a) precedes (b): by rule X
- (b) precedes (d): by rule 4
- (d) precedes (e): by the load value axiom. Otherwise, if (e) preceded (d), then (d) would be required to return the value 1. (This is a perfectly legal execution; it’s just not the one in question)
- (e) precedes (f): by rule X
- (f) precedes (h): by rule 4
- (h) precedes (a): by the load value axiom, as above.
The global memory order must be a total order and cannot be cyclic, because a cycle would imply that every event in the cycle happens before itself, which is impossible. Therefore, the execution proposed above would be forbidden, and hence the addition of rule X would forbid implementations with store buffer forwarding, which would clearly be undesirable.
Nevertheless, even if (b) precedes (a) and/or (f) precedes (e) in the global memory order, the only sensible possibility in this example is for (b) to return the value written by (a), and likewise for (f) and (e). This combination of circumstances is what leads to the second option in the definition of the load value axiom. Even though (b) precedes (a) in the global memory order, (a) will still be visible to (b) by virtue of sitting in the store buffer at the time (b) executes. Therefore, even if (b) precedes (a) in the global memory order, (b) should return the value written by (a) because (a) precedes (b) in program order. Likewise for (e) and (f).
Table 70. The PPOCA store buffer forwarding litmus test (outcome permitted)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | li t1, 1 | ||
| (a) | sw t1,0(s0) | LOOP: | |
| (b) | fence w,w | (d) | lw a0,0(s1) |
| (c) | sw t1,0(s1) | beqz a0, LOOP | |
| (e) | sw t1,0(s2) | ||
| (f) | lw a1,0(s2) | ||
| xor a2,a1,a1 | |||
| add s0,s0,a2 | |||
| (g) | lw a2,0(s0) | ||
Outcome: a0=1, a1=1, a2=0 | |||
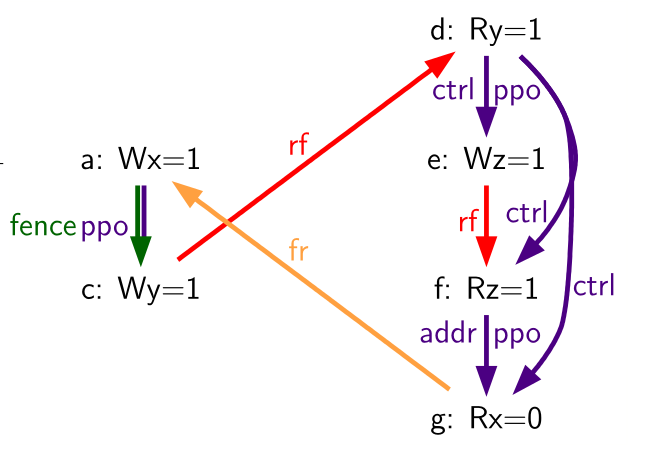
Another test that highlights the behavior of store buffers is shown in Table 70. In this example, (d) is ordered before (e) because of the control dependency, and (f) is ordered before (g) because of the address dependency. However, (e) is not necessarily ordered before (f), even though (f) returns the value written by (e). This could correspond to the following sequence of events:
- (e) executes speculatively and enters the second hart’s private store buffer (but does not drain to memory)
- (f) executes speculatively and forwards its return value 1 from (e) in the store buffer
- (g) executes speculatively and reads the value 0 from memory
- (a) executes, enters the first hart’s private store buffer, and drains to memory
- (b) executes and retires
- (c) executes, enters the first hart’s private store buffer, and drains to memory
- (d) executes and reads the value 1 from memory
- (e), (f), and (g) commit, since the speculation turned out to be correct
- (e) drains from the store buffer to memory
B.1.3.3 Atomicity axiom
Atomicity Axiom (for Aligned Atomics): If r and w are paired load and store operations generated by aligned LR and SC instructions in a hart h, s is a store to byte x, and r returns a value written by s, then s must precede w in the global memory order, and there can be no store from a hart other than h to byte x following s and preceding w in the global memory order.
The RISC-V architecture decouples the notion of atomicity from the notion of ordering. Unlike architectures such as TSO, RISC-V atomics under RVWMO do not impose any ordering requirements by default. Ordering semantics are only guaranteed by the PPO rules that otherwise apply.
RISC-V contains two types of atomics: AMOs and LR/SC pairs. These conceptually behave differently, in the following way. LR/SC behave as if the old value is brought up to the core, modified, and written back to memory, all while a reservation is held on that memory location. AMOs on the other hand conceptually behave as if they are performed directly in memory. AMOs are therefore inherently atomic, while LR/SC pairs are atomic in the slightly different sense that the memory location in question will not be modified by another hart during the time the original hart holds the reservation.
Table 71. In all four (independent) instances, the final store-conditional instruction is permitted but not guaranteed to succeed.
| (a) lr.d a0, 0(s0) | (a) lr.d a0, 0(s0) | (a) lr.w a0, 0(s0) | (a) lr.w a0, 0(s0) |
|---|---|---|---|
| (b) sd t1, 0(s0) | (b) sw t1, 4(s0) | (b) sw t1, 4(s0) | (b) sw t1, 4(s0) |
| (c) sc.d t3, t2, 0(s0) | (c) sc.d t3, t2, 0(s0) | (c) sc.w t3, t2, 0(s0) | (c) addi s0, s0, 8 |
| (d) sc.w t3, t2, 0(s0) |
The atomicity axiom forbids stores from other harts from being interleaved in global memory order between an LR and the SC paired with that LR. The atomicity axiom does not forbid loads from being interleaved between the paired operations in program order or in the global memory order, nor does it forbid stores from the same hart or stores to non-overlapping locations from appearing between the paired operations in either program order or in the global memory order. For example, the SC instructions in Table 71 may (but are not guaranteed to) succeed. None of those successes would violate the atomicity axiom, because the intervening non-conditional stores are from the same hart as the paired load-reserved and store-conditional instructions. This way, a memory system that tracks memory accesses at cache line granularity (and which therefore will see the four snippets of Table 71 as identical) will not be forced to fail a store-conditional instruction that happens to (falsely) share another portion of the same cache line as the memory location being held by the reservation.
The atomicity axiom also technically supports cases in which the LR and SC touch different addresses and/or use different access sizes; however, use cases for such behaviors are expected to be rare in practice. Likewise, scenarios in which stores from the same hart between an LR/SC pair actually overlap the memory location(s) referenced by the LR or SC are expected to be rare compared to scenarios where the intervening store may simply fall onto the same cache line.
B.1.3.4 Progress axiom
Progress Axiom: No memory operation may be preceded in the global memory order by an infinite sequence of other memory operations.
The progress axiom ensures a minimal forward progress guarantee. It ensures that stores from one hart will eventually be made visible to other harts in the system in a finite amount of time, and that loads from other harts will eventually be able to read those values (or successors thereof). Without this rule, it would be legal, for example, for a spinlock to spin infinitely on a value, even with a store from another hart unlocking the spinlock.
The progress axiom is intended not to impose any other notion of fairness, latency, or quality of service onto the harts in a RISC-V implementation. Any stronger notions of fairness are up to the rest of the ISA and/or up to the platform and/or device to define and implement.
The forward progress axiom will in almost all cases be naturally satisfied by any standard cache coherence protocol. Implementations with non-coherent caches may have to provide some other mechanism to ensure the eventual visibility of all stores (or successors thereof) to all harts.
B.1.3.5 Overlapping-Address Orderings (Rules 1-3)
Rule 1: b is a store, and a and b access overlapping memory addresses
Rule 2: a and b are loads, x is a byte read by both a and b, there is no store to x between a and b in program order, and a and b return values for x written by different memory operations
Rule 3: a is generated by an AMO or SC instruction, b is a load, and b returns a value written by a
Same-address orderings where the latter is a store are straightforward: a load or store can never be reordered with a later store to an overlapping memory location. From a microarchitecture perspective, generally speaking, it is difficult or impossible to undo a speculatively reordered store if the speculation turns out to be invalid, so such behavior is simply disallowed by the model. Same-address orderings from a store to a later load, on the other hand, do not need to be enforced. As discussed in Load value axiom, this reflects the observable behavior of implementations that forward values from buffered stores to later loads.
Same-address load-load ordering requirements are far more subtle. The basic requirement is that a younger load must not return a value that is older than a value returned by an older load in the same hart to the same address. This is often known as CoRR (Coherence for Read-Read pairs), or as part of a broader coherence or sequential consistency per location requirement. Some architectures in the past have relaxed same-address load-load ordering, but in hindsight this is generally considered to complicate the programming model too much, and so RVWMO requires CoRR ordering to be enforced. However, because the global memory order corresponds to the order in which loads perform rather than the ordering of the values being returned, capturing CoRR requirements in terms of the global memory order requires a bit of indirection.
Table 72. A litmus test MP+fence.w.w+fri-rfi-addr (outcome permitted)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | li t2, 2 | ||
| (a) | sw t1,0(s0) | (d) | lw a0,0(s1) |
| (b) | fence w, w | (e) | sw t2,0(s1) |
| (c) | sw t1,0(s1) | (f) | lw a1,0(s1) |
| (g) | xor t3,a1,a1 | ||
| (h) | add s0,s0,t3 | ||
| (i) | lw a2,0(s0) | ||
Outcome: a0=1, a1=2, a2=0 | |||
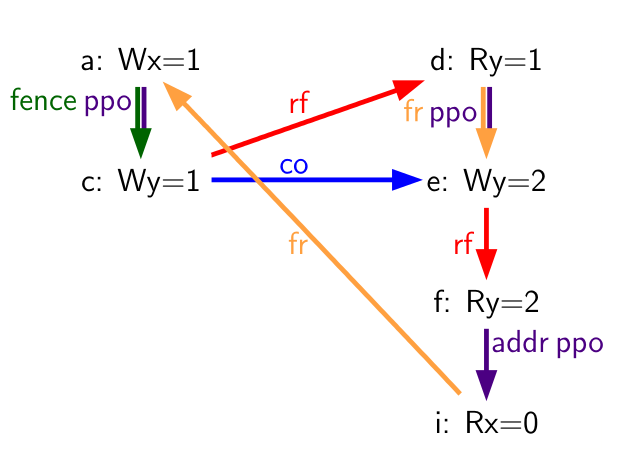
Consider the litmus test of Table 72, which is one particular instance of the more general fri-rfi pattern. The term fri-rfi refers to the sequence (d), (e), (f): (d) from-reads (i.e., reads from an earlier write than) (e) which is the same hart, and (f) reads from (e) which is in the same hart.
From a microarchitectural perspective, outcome a0=1, a1=2, a2=0 is
legal (as are various other less subtle outcomes). Intuitively, the
following would produce the outcome in question:
- (d) stalls (for whatever reason; perhaps it’s stalled waiting for some other preceding instruction)
- (e) executes and enters the store buffer (but does not yet drain to memory)
- (f) executes and forwards from (e) in the store buffer
- (g), (h), and (i) execute
- (a) executes and drains to memory, (b) executes, and (c) executes and drains to memory
- (d) unstalls and executes
- (e) drains from the store buffer to memory
This corresponds to a global memory order of (f), (i), (a), (c), (d), (e). Note that even though (f) performs before (d), the value returned by (f) is newer than the value returned by (d). Therefore, this execution is legal and does not violate the CoRR requirements.
Likewise, if two back-to-back loads return the values written by the same store, then they may also appear out-of-order in the global memory order without violating CoRR. Note that this is not the same as saying that the two loads return the same value, since two different stores may write the same value.
Table 73. Litmus test RSW (outcome permitted)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | (d) | lw a0,0(s1) | |
| (a) | sw t1,0(s0) | (e) | xor t2,a0,a0 |
| (b) | fence w, w | (f) | add s4,s2,t2 |
| (c) | sw t1,0(s1) | (g) | lw a1,0(s4) |
| (h) | lw a2,0(s2) | ||
| (i) | xor t3,a2,a2 | ||
| (j) | add s0,s0,t3 | ||
| (k) | lw a3,0(s0) | ||
Outcome: a0=1, a1=v, a2=v, a3=0 | |||
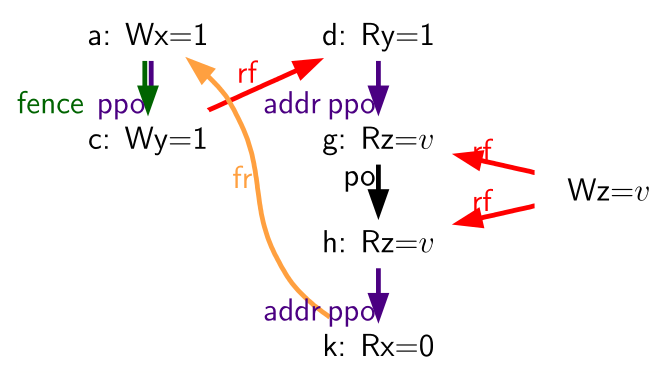
Consider the litmus test of Table 73.
The outcome a0=1, a1=v, a2=v, a3=0 (where v is
some value written by another hart) can be observed by allowing (g) and
(h) to be reordered. This might be done speculatively, and the
speculation can be justified by the microarchitecture (e.g., by snooping
for cache invalidations and finding none) because replaying (h) after
(g) would return the value written by the same store anyway. Hence
assuming a1 and a2 would end up with the same value written by the
same store anyway, (g) and (h) can be legally reordered. The global
memory order corresponding to this execution would be
(h),(k),(a),(c),(d),(g).
Executions of the test in Table 73 in
which a1 does not equal a2 do in fact require that (g) appears
before (h) in the global memory order. Allowing (h) to appear before (g)
in the global memory order would in that case result in a violation of
CoRR, because then (h) would return an older value than that returned by
(g). Therefore, rule 2 forbids this CoRR violation
from occurring. As such, rule 2 strikes a careful
balance between enforcing CoRR in all cases while simultaneously being
weak enough to permit RSW and fri-rfi patterns that commonly
appear in real microarchitectures.
There is one more overlapping-address rule: rule 3 simply states that a value cannot be returned from an AMO or SC to a subsequent load until the AMO or SC has (in the case of the SC, successfully) performed globally. This follows somewhat naturally from the conceptual view that both AMOs and SC instructions are meant to be performed atomically in memory. However, notably, rule 3 states that hardware may not even non-speculatively forward the value being stored by an AMOSWAP to a subsequent load, even though for AMOSWAP that store value is not actually semantically dependent on the previous value in memory, as is the case for the other AMOs. The same holds true even when forwarding from SC store values that are not semantically dependent on the value returned by the paired LR.
The three PPO rules above also apply when the memory accesses in question only overlap partially. This can occur, for example, when accesses of different sizes are used to access the same object. Note also that the base addresses of two overlapping memory operations need not necessarily be the same for two memory accesses to overlap. When misaligned memory accesses are being used, the overlapping-address PPO rules apply to each of the component memory accesses independently.
B.1.3.6 Fences (Rule 4)
Rule 4: There is a FENCE instruction that orders a before b
By default, the FENCE instruction ensures that all memory accesses from instructions preceding the fence in program order (the predecessor set) appear earlier in the global memory order than memory accesses from instructions appearing after the fence in program order (the successor set). However, fences can optionally further restrict the predecessor set and/or the successor set to a smaller set of memory accesses in order to provide some speedup. Specifically, fences have PR, PW, SR, and SW bits which restrict the predecessor and/or successor sets. The predecessor set includes loads (resp. stores) if and only if PR (resp. PW) is set. Similarly, the successor set includes loads (resp. stores) if and only if SR (resp. SW) is set.
The FENCE encoding currently has nine non-trivial combinations of the four bits PR, PW, SR, and SW, plus one extra encoding FENCE.TSO which facilitates mapping of acquire+release or RVTSO semantics. The remaining seven combinations have empty predecessor and/or successor sets and hence are no-ops. Of the ten non-trivial options, six are commonly used in practice:
- FENCE RW,RW
- FENCE.TSO
- FENCE RW,W
- FENCE R,RW
- FENCE R,R
- FENCE W,W
FENCE instructions using other combinations of PR, PW, SR, and SW are not normally used in the Linux or C++ memory models but are otherwise well defined.
Finally, we note that since RISC-V uses a multi-copy atomic memory model, programmers can reason about fences bits in a thread-local manner. Fences in RISC-V are not cumulative, as they are in some non-multi-copy-atomic memory models.
B.1.3.7 Explicit Synchronization (Rules 5-8)
An acquire operation, as would be used at the start of a critical section, requires all memory operations following the acquire in program order to also follow the acquire in the global memory order. This ensures, for example, that all loads and stores inside the critical section are up to date with respect to the synchronization variable being used to protect it. Acquire ordering can be enforced in one of two ways: with an acquire annotation, which enforces ordering with respect to just the synchronization variable itself, or with a FENCE R,RW, which enforces ordering with respect to all previous loads.
sd x1, (a1) # Arbitrary unrelated store
ld x2, (a2) # Arbitrary unrelated load
li t0, 1 # Initialize swap value.
again:
amoswap.w.aq t0, t0, (a0) # Attempt to acquire lock.
bnez t0, again # Retry if held.
# ...
# Critical section.
# ...
amoswap.w.rl x0, x0, (a0) # Release lock by storing 0.
sd x3, (a3) # Arbitrary unrelated store
ld x4, (a4) # Arbitrary unrelated load
Consider Example 1.
Because this example uses aq, the loads and stores in the critical
section are guaranteed to appear in the global memory order after the
AMOSWAP used to acquire the lock. However, assuming a0, a1, and a2
point to different memory locations, the loads and stores in the
critical section may or may not appear after the Arbitrary unrelated
load at the beginning of the example in the global memory order.
sd x1, (a1) # Arbitrary unrelated store
ld x2, (a2) # Arbitrary unrelated load
li t0, 1 # Initialize swap value.
again:
amoswap.w t0, t0, (a0) # Attempt to acquire lock.
fence r, rw # Enforce "acquire" memory ordering
bnez t0, again # Retry if held.
# ...
# Critical section.
# ...
fence rw, w # Enforce "release" memory ordering
amoswap.w x0, x0, (a0) # Release lock by storing 0.
sd x3, (a3) # Arbitrary unrelated store
ld x4, (a4) # Arbitrary unrelated load
Now, consider the alternative in Example 2. In this case, even though the AMOSWAP does not enforce ordering with an aq bit, the fence nevertheless enforces that the acquire AMOSWAP appears earlier in the global memory order than all loads and stores in the critical section. Note, however, that in this case, the fence also enforces additional orderings: it also requires that the Arbitrary unrelated load at the start of the program appears earlier in the global memory order than the loads and stores of the critical section. (This particular fence does not, however, enforce any ordering with respect to the Arbitrary unrelated store at the start of the snippet.) In this way, fence-enforced orderings are slightly coarser than orderings enforced by .aq.
Release orderings work exactly the same as acquire orderings, just in the opposite direction. Release semantics require all loads and stores preceding the release operation in program order to also precede the release operation in the global memory order. This ensures, for example, that memory accesses in a critical section appear before the lock-releasing store in the global memory order. Just as for acquire semantics, release semantics can be enforced using release annotations or with a FENCE RW,W operation. Using the same examples, the ordering between the loads and stores in the critical section and the Arbitrary unrelated store at the end of the code snippet is enforced only by the FENCE RW,W in Example 2, not by the rl in Example 1.
With RCpc annotations alone, store-release-to-load-acquire ordering is not enforced. This facilitates the porting of code written under the TSO and/or RCpc memory models. To enforce store-release-to-load-acquire ordering, the code must use store-release-RCsc and load-acquire-RCsc operations so that PPO rule 7 applies. RCpc alone is sufficient for many use cases in C/C++ but is insufficient for many other use cases in C/C++, Java, and Linux, to name just a few examples; see Memory Porting for details.
PPO rule 8 indicates that an SC must appear after its paired LR in the global memory order. This will follow naturally from the common use of LR/SC to perform an atomic read-modify-write operation due to the inherent data dependency. However, PPO rule 8 also applies even when the value being stored does not syntactically depend on the value returned by the paired LR.
Lastly, we note that, as with fences, ordering annotations are not cumulative.
B.1.3.8 Syntactic Dependencies (Rules 9-11)
Dependencies from a load to a later memory operation in the same hart are respected by the RVWMO memory model. The Alpha memory model was notable for choosing not to enforce the ordering of such dependencies, but most modern hardware and software memory models consider allowing dependent instructions to be reordered too confusing and counterintuitive. Furthermore, modern code sometimes intentionally uses such dependencies as a particularly lightweight ordering enforcement mechanism.
The terms in Section 3.1.1.2 work as follows. Instructions
are said to carry dependencies from their
source register(s) to their destination register(s) whenever the value
written into each destination register is a function of the source
register(s). For most instructions, this means that the destination
register(s) carry a dependency from all source register(s). However,
there are a few notable exceptions. In the case of memory instructions,
the value written into the destination register ultimately comes from
the memory system rather than from the source register(s) directly, and
so this breaks the chain of dependencies carried from the source
register(s). In the case of unconditional jumps, the value written into
the destination register comes from the current pc (which is never
considered a source register by the memory model), and so likewise, JALR
(the only jump with a source register) does not carry a dependency from
rs1 to rd.
(a) fadd f3,f1,f2
(b) fadd f6,f4,f5
(c) csrrs a0,fflags,x0
The notion of accumulating into a destination register rather than
writing into it reflects the behavior of CSRs such as fflags. In
particular, an accumulation into a register does not clobber any
previous writes or accumulations into the same register. For example, in
(c) has a syntactic dependency on both (a) and (b) via fflags, a destination register that both (a) and (b) implicitly accumulate into, (c) has a syntactic dependency on both (a) and (b).
Like other modern memory models, the RVWMO memory model uses syntactic
rather than semantic dependencies. In other words, this definition
depends on the identities of the registers being accessed by different
instructions, not the actual contents of those registers. This means
that an address, control, or data dependency must be enforced even if
the calculation could seemingly be optimized away. This choice
ensures that RVWMO remains compatible with code that uses these false
syntactic dependencies as a lightweight ordering mechanism.
ld a1,0(s0)
xor a2,a1,a1
add s1,s1,a2
ld a5,0(s1)
For example, there is a syntactic address dependency from the memory
operation generated by the first instruction to the memory operation
generated by the last instruction in
A syntactic address dependency, even though a1 XOR
a1 is zero and hence has no effect on the address accessed by the
second load.
The benefit of using dependencies as a lightweight synchronization mechanism is that the ordering enforcement requirement is limited only to the specific two instructions in question. Other non-dependent instructions may be freely reordered by aggressive implementations. One alternative would be to use a load-acquire, but this would enforce ordering for the first load with respect to all subsequent instructions. Another would be to use a FENCE R,R, but this would include all previous and all subsequent loads, making this option more expensive.
lw x1,0(x2)
bne x1,x0,next
sw x3,0(x4)
next: sw x5,0(x6)
Control dependencies behave differently from address and data
dependencies in the sense that a control dependency always extends to
all instructions following the original target in program order.
Consider A syntactic control dependency the
instruction at next will always execute, but the memory operation
generated by that last instruction nevertheless still has a control
dependency from the memory operation generated by the first instruction.
lw x1,0(x2)
bne x1,x0,next
next: sw x3,0(x4)
Likewise, consider Another syntactic control dependency. Even though both branch outcomes have the same target, there is still a control dependency from the memory operation generated by the first instruction in this snippet to the memory operation generated by the last instruction. This definition of control dependency is subtly stronger than what might be seen in other contexts (e.g., C++), but it conforms with standard definitions of control dependencies in the literature.
Notably, PPO rules 9-11 are also intentionally designed to respect dependencies that originate from the output of a successful store-conditional instruction. Typically, an SC instruction will be followed by a conditional branch checking whether the outcome was successful; this implies that there will be a control dependency from the store operation generated by the SC instruction to any memory operations following the branch. PPO rule 11 in turn implies that any subsequent store operations will appear later in the global memory order than the store operation generated by the SC. However, since control, address, and data dependencies are defined over memory operations, and since an unsuccessful SC does not generate a memory operation, no order is enforced between unsuccessful SC and its dependent instructions. Moreover, since SC is defined to carry dependencies from its source registers to rd only when the SC is successful, an unsuccessful SC has no effect on the global memory order.
Table 74. A variant of the LB litmus test (outcome forbidden)
| Initial values: 0(s0)=1; 0(s2)=1 | |||
| Hart 0 | Hart 1 | ||
| (a) | ld a0,0(s0) | (e) | ld a3,0(s2) |
| (b) | lr a1,0(s1) | (f) | sd a3,0(s0) |
| (c) | sc a2,a0,0(s1) | ||
| (d) | sd a2,0(s2) | ||
Outcome: a0=0, a3=0 | |||
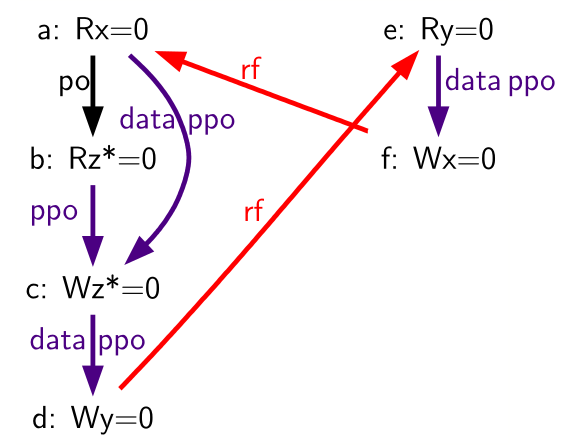
In addition, the choice to respect dependencies originating at
store-conditional instructions ensures that certain out-of-thin-air-like
behaviors will be prevented. Consider
Table 74. Suppose a
hypothetical implementation could occasionally make some early guarantee
that a store-conditional operation will succeed. In this case, (c) could
return 0 to a2 early (before actually executing), allowing the
sequence (d), (e), (f), (a), and then (b) to execute, and then (c) might
execute (successfully) only at that point. This would imply that (c)
writes its own success value to 0(s1)! Fortunately, this situation and
others like it are prevented by the fact that RVWMO respects
dependencies originating at the stores generated by successful SC
instructions.
We also note that syntactic dependencies between instructions only have
any force when they take the form of a syntactic address, control,
and/or data dependency. For example: a syntactic dependency between two
F instructions via one of the accumulating CSRs in
Section 3.1.3 does not imply
that the two F instructions must be executed in order. Such a
dependency would only serve to ultimately set up later a dependency from
both F instructions to a later CSR instruction accessing the CSR
flag in question.
B.1.3.9 Pipeline Dependencies (Rules 12-13)
Rule 12: b is a load, and there exists some store m between a and b in program order such that m has an address or data dependency on a, and b returns a value written by m
Rule 13: b is a store, and there exists some instruction m between a and b in program order such that m has an address dependency on a
Table 75. Because of PPO rule 12 and the data dependency from (d) to (e), (d) must also precede (f) in the global memory order (outcome forbidden)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | (d) | lw a0, 0(s1) | |
| (a) | sw t1,0(s0) | (e) | sw a0, 0(s2) |
| (b) | fence w, w | (f) | lw a1, 0(s2) |
| (c) | sw t1,0(s1) | xor a2,a1,a1 | |
| add s0,s0,a2 | |||
| (g) | lw a3,0(s0) | ||
Outcome: a0=1, a3=0 | |||
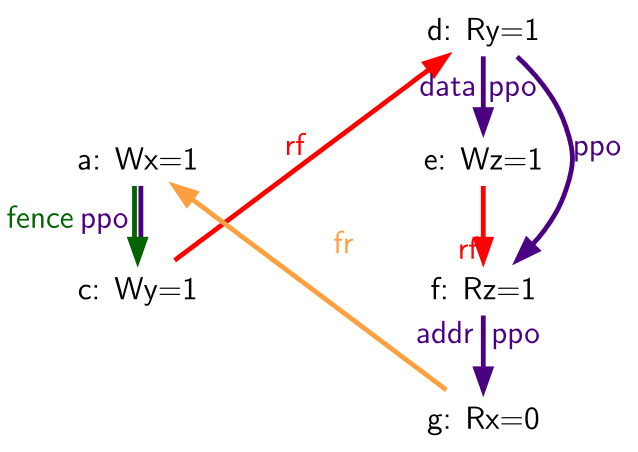
PPO rules 12 and 13 reflect behaviors of almost all real processor pipeline implementations. Rule 12 states that a load cannot forward from a store until the address and data for that store are known. Consider Table 75 (f) cannot be executed until the data for (e) has been resolved, because (f) must return the value written by (e) (or by something even later in the global memory order), and the old value must not be clobbered by the write-back of (e) before (d) has had a chance to perform. Therefore, (f) will never perform before (d) has performed.
Table 76. Because of the extra store between (e) and (g), (d) no longer necessarily precedes (g) (outcome permitted)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | li t1, 1 | ||
| (a) | sw t1,0(s0) | (d) | lw a0, 0(s1) |
| (b) | fence w, w | (e) | sw a0, 0(s2) |
| (c) | sw t1,0(s1) | (f) | sw t1, 0(s2) |
| (g) | lw a1, 0(s2) | ||
| xor a2,a1,a1 | |||
| add s0,s0,a2 | |||
| (h) | lw a3,0(s0) | ||
Outcome: a0=1, a3=0 | |||
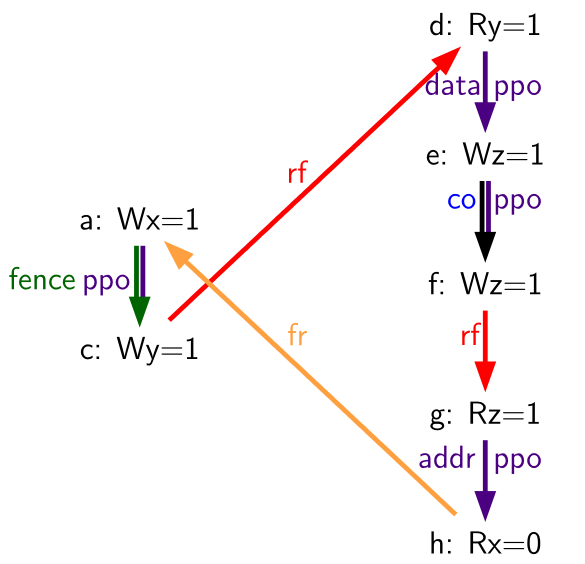
If there were another store to the same address in between (e) and (f), as in Table 77, then (f) would no longer be dependent on the data of (e) being resolved, and hence the dependency of (f) on (d), which produces the data for (e), would be broken.
Rule 13 makes a similar observation to the previous rule: a store cannot be performed at memory until all previous loads that might access the same address have themselves been performed. Such a load must appear to execute before the store, but it cannot do so if the store were to overwrite the value in memory before the load had a chance to read the old value. Likewise, a store generally cannot be performed until it is known that preceding instructions will not cause an exception due to failed address resolution, and in this sense, rule 13 can be seen as somewhat of a special case of rule 11.
Table 77. Because of the address dependency from (d) to (e), (d) also precedes (f) (outcome forbidden)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | |||
| (a) | lw a0,0(s0) | (d) | lw a1, 0(s1) |
| (b) | fence rw,rw | (e) | lw a2, 0(a1) |
| (c) | sw s2,0(s1) | (f) | sw t1, 0(s0) |
Outcome: a0=1, a1=t | |||
Consider Table 77 (f) cannot be
executed until the address for (e) is resolved, because it may turn out
that the addresses match; i.e., that a1=s0. Therefore, (f) cannot be
sent to memory before (d) has executed and confirmed whether the
addresses do indeed overlap.
B.1.4 Beyond Main Memory
RVWMO does not currently attempt to formally describe how FENCE.I,
SFENCE.VMA, I/O fences, and PMAs behave. All of these behaviors will be
described by future formalizations. In the meantime, the behavior of
FENCE.I is described in Zifencei, the
behavior of SFENCE.VMA is described in sfence.vma, and the behavior
of I/O fences and the effects of PMAs are described below.
B.1.4.1 Coherence and Cacheability
The RISC-V Privileged ISA defines Physical Memory Attributes (PMAs) which specify, among other things, whether portions of the address space are coherent and/or cacheable. See the RISC-V Privileged ISA Specification for the complete details. Here, we simply discuss how the various details in each PMA relate to the memory model:
- Main memory vs.I/O, and I/O memory ordering PMAs: the memory model as defined applies to main memory regions. I/O ordering is discussed below.
- Supported access types and atomicity PMAs: the memory model is simply applied on top of whatever primitives each region supports.
- Cacheability PMAs: the cacheability PMAs in general do not affect the memory model. Non-cacheable regions may have more restrictive behavior than cacheable regions, but the set of allowed behaviors does not change regardless. However, some platform-specific and/or device-specific cacheability settings may differ.
- Coherence PMAs: The memory consistency model for memory regions marked as non-coherent in PMAs is currently platform-specific and/or device-specific: the load-value axiom, the atomicity axiom, and the progress axiom all may be violated with non-coherent memory. Note however that coherent memory does not require a hardware cache coherence protocol. The RISC-V Privileged ISA Specification suggests that hardware-incoherent regions of main memory are discouraged, but the memory model is compatible with hardware coherence, software coherence, implicit coherence due to read-only memory, implicit coherence due to only one agent having access, or otherwise.
- Idempotency PMAs: Idempotency PMAs are used to specify memory regions for which loads and/or stores may have side effects, and this in turn is used by the microarchitecture to determine, e.g., whether prefetches are legal. This distinction does not affect the memory model.
B.1.4.2 I/O Ordering
For I/O, the load value axiom and atomicity axiom in general do not apply, as both reads and writes might have device-specific side effects and may return values other than the value written by the most recent store to the same address. Nevertheless, the following preserved program order rules still generally apply for accesses to I/O memory: memory access a precedes memory access b in global memory order if a precedes b in program order and one or more of the following holds:
- a precedes b in preserved program order as defined in Section 3.1, with the exception that acquire and release ordering annotations apply only from one memory operation to another memory operation and from one I/O operation to another I/O operation, but not from a memory operation to an I/O nor vice versa
- a and b are accesses to overlapping addresses in an I/O region
- a and b are accesses to the same strongly ordered I/O region
- a and b are accesses to I/O regions, and the channel associated with the I/O region accessed by either a or b is channel 1
- a and b are accesses to I/O regions associated with the same channel (except for channel 0)
Note that the FENCE instruction distinguishes between main memory operations and I/O operations in its predecessor and successor sets. To enforce ordering between I/O operations and main memory operations, code must use a FENCE with PI, PO, SI, and/or SO, plus PR, PW, SR, and/or SW. For example, to enforce ordering between a write to main memory and an I/O write to a device register, a FENCE W,O or stronger is needed.
sd t0, 0(a0)
fence w,o
sd a0, 0(a1)
When a fence is in fact used, implementations must assume that the
device may attempt to access memory immediately after receiving the MMIO
signal, and subsequent memory accesses from that device to memory must
observe the effects of all accesses ordered prior to that MMIO
operation. In other words, in Ordering memory and I/O accesses,
suppose 0(a0) is in main memory and 0(a1) is the address of a device
register in I/O memory. If the device accesses 0(a0) upon receiving
the MMIO write, then that load must conceptually appear after the first
store to 0(a0) according to the rules of the RVWMO memory model. In
some implementations, the only way to ensure this will be to require
that the first store does in fact complete before the MMIO write is
issued. Other implementations may find ways to be more aggressive, while
others still may not need to do anything different at all for I/O and
main memory accesses. Nevertheless, the RVWMO memory model does not
distinguish between these options; it simply provides an
implementation-agnostic mechanism to specify the orderings that must be
enforced.
Many architectures include separate notions of ordering and completion fences, especially as it relates to I/O (as opposed to regular main memory). Ordering fences simply ensure that memory operations stay in order, while completion fences ensure that predecessor accesses have all completed before any successors are made visible. RISC-V does not explicitly distinguish between ordering and completion fences. Instead, this distinction is simply inferred from different uses of the FENCE bits.
For implementations that conform to the RISC-V Unix Platform Specification, I/O devices and DMA operations are required to access memory coherently and via strongly ordered I/O channels. Therefore, accesses to regular main memory regions that are concurrently accessed by external devices can also use the standard synchronization mechanisms. Implementations that do not conform to the Unix Platform Specification and/or in which devices do not access memory coherently will need to use mechanisms (which are currently platform-specific or device-specific) to enforce coherency.
I/O regions in the address space should be considered non-cacheable regions in the PMAs for those regions. Such regions can be considered coherent by the PMA if they are not cached by any agent.
The ordering guarantees in this section may not apply beyond a platform-specific boundary between the RISC-V cores and the device. In particular, I/O accesses sent across an external bus (e.g., PCIe) may be reordered before they reach their ultimate destination. Ordering must be enforced in such situations according to the platform-specific rules of those external devices and buses.
B.1.5 Code Porting and Mapping Guidelines
Table 78. Mappings from TSO operations to RISC-V operations
| x86/TSO Operation | RVWMO Mapping |
|---|---|
| Load | l\{b|h|w|d\}; fence r,rw |
| Store | fence rw,w; s\{b|h|w|d\} |
| Atomic RMW | loop:lr.\{w|d\}.aq; \<op\>; sc.\{w|d\}.aqrl; bnez loop |
| Fence | fence rw,rw |
Table 78 provides a mapping from TSO memory operations onto RISC-V memory instructions. Normal x86 loads and stores are all inherently acquire-RCpc and release-RCpc operations: TSO enforces all load-load, load-store, and store-store ordering by default. Therefore, under RVWMO, all TSO loads must be mapped onto a load followed by FENCE R,RW, and all TSO stores must be mapped onto FENCE RW,W followed by a store. TSO atomic read-modify-writes and x86 instructions using the LOCK prefix are fully ordered and can be implemented either via an AMO with both aq and rl set, or via an LR with aq set, the arithmetic operation in question, an SC with both aq and rl set, and a conditional branch checking the success condition. In the latter case, the rl annotation on the LR turns out (for non-obvious reasons) to be redundant and can be omitted.
Alternatives to Table 78 are also possible. A TSO store can be mapped onto AMOSWAP with rl set. However, since RVWMO PPO Rule 3 forbids forwarding of values from AMOs to subsequent loads, the use of AMOSWAP for stores may negatively affect performance. A TSO load can be mapped using LR with aq set: all such LR instructions will be unpaired, but that fact in and of itself does not preclude the use of LR for loads. However, again, this mapping may also negatively affect performance if it puts more pressure on the reservation mechanism than was originally intended.
Table 79. Mappings from Power operations to RISC-V operations
| Power Operation | RVWMO Mapping |
|---|---|
| Load | l\{b|h|w|d\} |
| Load-Reserve | lr.\{w|d\} |
| Store | s\{b|h|w|d\} |
| Store-Conditional | sc.\{w|d\} |
lwsync | fence.tso |
sync | fence rw,rw |
isync | fence.i; fence r,r |
Table 79 provides a mapping from Power memory operations onto RISC-V memory instructions. Power ISYNC maps on RISC-V to a FENCE.I followed by a FENCE R,R; the latter fence is needed because ISYNC is used to define a control+control fence dependency that is not present in RVWMO.
Table 80. Mappings from ARM operations to RISC-V operations
| ARM Operation | RVWMO Mapping |
|---|---|
| Load | l\{b|h|w|d\} |
| Load-Acquire | fence rw, rw; l\{b|h|w|d\}; fence r,rw |
| Load-Exclusive | lr.\{w|d\} |
| Load-Acquire-Exclusive | lr.\{w|d\}.aqrl |
| Store | s\{b|h|w|d\} |
| Store-Release | fence rw,w; s\{b|h|w|d\} |
| Store-Exclusive | sc.\{w|d\} |
| Store-Release-Exclusive | sc.\{w|d\}.rl |
dmb | fence rw,rw |
dmb.ld | fence r,rw |
dmb.st | fence w,w |
isb | fence.i; fence r,r |
Table 80 provides a mapping from ARM memory operations onto RISC-V memory instructions. Since RISC-V does not currently have plain load and store opcodes with aq or rl annotations, ARM load-acquire and store-release operations should be mapped using fences instead. Furthermore, in order to enforce store-release-to-load-acquire ordering, there must be a FENCE RW,RW between the store-release and load-acquire; Table 80 enforces this by always placing the fence in front of each acquire operation. ARM load-exclusive and store-exclusive instructions can likewise map onto their RISC-V LR and SC equivalents, but instead of placing a FENCE RW,RW in front of an LR with aq set, we simply also set rl instead. ARM ISB maps on RISC-V to FENCE.I followed by FENCE R,R similarly to how ISYNC maps for Power.
Table 81. Mappings from Linux memory primitives to RISC-V primitives.
| Linux Operation | RVWMO Mapping |
|---|---|
smp_mb() | fence rw,rw |
smp_rmb() | fence r,r |
smp_wmb() | fence w,w |
dma_rmb() | fence r,r |
dma_wmb() | fence w,w |
mb() | fence iorw,iorw |
rmb() | fence ri,ri |
wmb() | fence wo,wo |
smp_load_acquire() | l\{b|h|w|d\}; fence r,rw |
smp_store_release() | fence.tso; s\{b|h|w|d\} |
| Linux Construct | RVWMO AMO Mapping |
atomic \<op\> relaxed | amo \<op\>.\{w|d\} |
atomic \<op\> acquire | amo \<op\>.\{w|d\}.aq |
atomic \<op\> release | amo \<op\>.\{w|d\}.rl |
atomic \<op\> | amo \<op\>.\{w|d\}.aqrl |
| Linux Construct | RVWMO LR/SC Mapping |
atomic \<op\> relaxed | loop:lr.\{w|d\}; \<op\>; sc.\{w|d\}; bnez loop |
atomic \<op\> acquire | loop:lr.\{w|d\}.aq; \<op\>; sc.\{w|d\}; bnez loop |
atomic \<op\> release | loop:lr.\{w|d\}; \<op\>; sc.\{w|d\}.aqrl<sup>*</sup>; bnez loop OR |
fence.tso; loop:lr.\{w|d\}; \<op \>; sc.\{w|d\}<sup>*</sup>; bnez loop | |
atomic \<op\> | loop:lr.\{w|d\}.aq; \<op\>; sc.\{w|d\}.aqrl; bnez loop |
With regards to Table 81, other constructs (such as spinlocks) should follow accordingly. Platforms or devices with non-coherent DMA may need additional synchronization (such as cache flush or invalidate mechanisms); currently any such extra synchronization will be device-specific.
Table 81 provides a mapping of Linux memory
ordering macros onto RISC-V memory instructions. The Linux fences
dma_rmb() and dma_wmb() map onto FENCE R,R and FENCE W,W,
respectively, since the RISC-V Unix Platform requires coherent DMA, but
would be mapped onto FENCE RI,RI and FENCE WO,WO, respectively, on a
platform with non-coherent DMA. Platforms with non-coherent DMA may also
require a mechanism by which cache lines can be flushed and/or
invalidated. Such mechanisms will be device-specific and/or standardized
in a future extension to the ISA.
The Linux mappings for release operations may seem stronger than necessary, but these mappings are needed to cover some cases in which Linux requires stronger orderings than the more intuitive mappings would provide. In particular, as of the time this text is being written, Linux is actively debating whether to require load-load, load-store, and store-store orderings between accesses in one critical section and accesses in a subsequent critical section in the same hart and protected by the same synchronization object. Not all combinations of FENCE RW,W/FENCE R,RW mappings with aq/rl mappings combine to provide such orderings. There are a few ways around this problem, including:
- Always use FENCE RW,W/FENCE R,RW, and never use aq/rl. This suffices but is undesirable, as it defeats the purpose of the aq/rl modifiers.
- Always use aq/rl, and never use FENCE RW,W/FENCE R,RW. This does not currently work due to the lack of load and store opcodes with aq and rl modifiers.
- Strengthen the mappings of release operations such that they would enforce sufficient orderings in the presence of either type of acquire mapping. This is the currently recommended solution, and the one shown in Table 81.
RVWMO Mapping: (a) lw a0, 0(s0) (b) fence.tso // vs. fence rw,w (c) sd x0,0(s1) … loop: (d) amoswap.d.aq a1,t1,0(s1) bnez a1,loop (e) lw a2,0(s2)
For example, the critical section ordering rule currently being debated by the Linux community would require (a) to be ordered before (e) in Orderings between critical sections in Linux. If that will indeed be required, then it would be insufficient for (b) to map as FENCE RW,W. That said, these mappings are subject to change as the Linux Kernel Memory Model evolves.
Linux Code:
(a) int r0 = *x;
(bc) spin_unlock(y, 0);
....
....
(d) spin_lock(y);
(e) int r1 = *z;
RVWMO Mapping:
(a) lw a0, 0(s0)
(b) fence.tso // vs. fence rw,w
(c) sd x0,0(s1)
....
loop:
(d) lr.d.aq a1,(s1)
bnez a1,loop
sc.d a1,t1,(s1)
bnez a1,loop
(e) lw a2,0(s2)
Table 82 provides a mapping of C11/C++11 atomic
operations onto RISC-V memory instructions. If load and store opcodes
with aq and rl modifiers are introduced, then the mappings in
Table 83 will suffice. Note however that
the two mappings only interoperate correctly if
atomic_\<op>(memory_order_seq_cst) is mapped using an LR that has both
aq and rl set.
Even more importantly, a Table 82 sequentially consistent store,
followed by a Table 83 sequentially consistent load
can be reordered unless the Table 82 mapping of stores is
strengthened by either adding a second fence or mapping the store
to amoswap.rl instead.
Table 82. Mappings from C/C++ primitives to RISC-V primitives.
| C/C++ Construct | RVWMO Mapping |
|---|---|
| Non-atomic load | l\{b|h|w|d\} |
atomic_load(memory_order_relaxed) | l\{b|h|w|d\} |
atomic_load(memory_order_acquire) | l\{b|h|w|d\}; fence r,rw |
atomic_load(memory_order_seq_cst) | fence rw,rw; l\{b|h|w|d\}; fence r,rw |
| Non-atomic store | s\{b|h|w|d\} |
atomic_store(memory_order_relaxed) | s\{b|h|w|d\} |
atomic_store(memory_order_release) | fence rw,w; s\{b|h|w|d\} |
atomic_store(memory_order_seq_cst) | fence rw,w; s\{b|h|w|d\} |
atomic_thread_fence(memory_order_acquire) | fence r,rw |
atomic_thread_fence(memory_order_release) | fence rw,w |
atomic_thread_fence(memory_order_acq_rel) | fence.tso |
atomic_thread_fence(memory_order_seq_cst) | fence rw,rw |
| C/C++ Construct | RVWMO AMO Mapping |
atomic_\<op\>(memory_order_relaxed) | amo\<op\>.\{w|d\} |
atomic_\<op\>(memory_order_acquire) | amo\<op\>.\{w|d\}.aq |
atomic_\<op\>(memory_order_release) | amo\<op\>.\{w|d\}.rl |
atomic_\<op\>(memory_order_acq_rel) | amo\<op\>.\{w|d\}.aqrl |
atomic_\<op\>(memory_order_seq_cst) | amo\<op\>.\{w|d\}.aqrl |
| C/C++ Construct | RVWMO LR/SC Mapping |
atomic_\<op\>(memory_order_relaxed) | loop:lr.\{w|d\}; \<op\>; sc.\{w|d\}; |
bnez loop | |
atomic_\<op\>(memory_order_acquire) | loop:lr.\{w|d\}.aq; \<op\>; sc.\{w|d\}; |
bnez loop | |
atomic_\<op\>(memory_order_release) | loop:lr.\{w|d\}; \<op\>; sc.\{w|d\}.rl; |
bnez loop | |
atomic_\<op\>(memory_order_acq_rel) | loop:lr.\{w|d\}.aq; \<op\>; sc.\{w|d\}.rl; |
bnez loop | |
atomic_\<op\>(memory_order_seq_cst) | loop:lr.\{w|d\}.aqrl; \<op\>; |
sc.\{w|d\}.rl; bnez loop |
Table 83. Hypothetical mappings from C/C++ primitives to RISC-V primitives, if native load-acquire and store-release opcodes are introduced.
| C/C++ Construct | RVWMO Mapping |
|---|---|
| Non-atomic load | l\{b|h|w|d\} |
atomic_load(memory_order_relaxed) | l\{b|h|w|d\} |
atomic_load(memory_order_acquire) | l\{b|h|w|d\}.aq |
atomic_load(memory_order_seq_cst) | l\{b|h|w|d\}.aq |
| Non-atomic store | s\{b|h|w|d\} |
atomic_store(memory_order_relaxed) | s\{b|h|w|d\} |
atomic_store(memory_order_release) | s\{b|h|w|d\}.rl |
atomic_store(memory_order_seq_cst) | s\{b|h|w|d\}.rl |
atomic_thread_fence(memory_order_acquire) | fence r,rw |
atomic_thread_fence(memory_order_release) | fence rw,w |
atomic_thread_fence(memory_order_acq_rel) | fence.tso |
atomic_thread_fence(memory_order_seq_cst) | fence rw,rw |
| C/C++ Construct | RVWMO AMO Mapping |
atomic_\<op\>(memory_order_relaxed) | amo\<op\>.\{w|d\} |
atomic_\<op\>(memory_order_acquire) | amo\<op\>.\{w|d\}.aq |
atomic_\<op\>(memory_order_release) | amo\<op\>.\{w|d\}.rl |
atomic_\<op\>(memory_order_acq_rel) | amo\<op\>.\{w|d\}.aqrl |
atomic_\<op\>(memory_order_seq_cst) | amo\<op\>.\{w|d\}.aqrl |
| C/C++ Construct | RVWMO LR/SC Mapping |
atomic_\<op\>(memory_order_relaxed) | lr.\{w|d\}; \<op\>; sc.\{w|d\} |
atomic_\<op\>(memory_order_acquire) | lr.\{w|d\}.aq; \<op\>; sc.\{w|d\} |
atomic_\<op\>(memory_order_release) | lr.\{w|d\}; \<op\>; sc.\{w|d\}.rl |
atomic_\<op\>(memory_order_acq_rel) | lr.\{w|d\}.aq; \<op\>; sc.\{w|d\}.rl |
atomic_\<op\>(memory_order_seq_cst) | lr.\{w|d\}.aq<sup>*</sup> \<op\>; sc.\{w|d\}.rl |
* must be lr.\{w|d\}.aqrl in order to interoperate with code mapped per Table 82 | |
Any AMO can be emulated by an LR/SC pair, but care must be taken to
ensure that any PPO orderings that originate from the LR are also made
to originate from the SC, and that any PPO orderings that terminate at
the SC are also made to terminate at the LR. For example, the LR must
also be made to respect any data dependencies that the AMO has, given
that load operations do not otherwise have any notion of a data
dependency. Likewise, the effect a FENCE R,R elsewhere in the same hart
must also be made to apply to the SC, which would not otherwise respect
that fence. The emulator may achieve this effect by simply mapping AMOs
onto lr.aq; \<op>; sc.aqrl, matching the mapping used elsewhere for
fully ordered atomics.
These C11/C++11 mappings require the platform to provide the following Physical Memory Attributes (as defined in the RISC-V Privileged ISA) for all memory:
- main memory
- coherent
- AMOArithmetic
- RsrvEventual
Platforms with different attributes may require different mappings, or require platform-specific SW (e.g., memory-mapped I/O).
B.1.6 Implementation Guidelines
The RVWMO and RVTSO memory models by no means preclude microarchitectures from employing sophisticated speculation techniques or other forms of optimization in order to deliver higher performance. The models also do not impose any requirement to use any one particular cache hierarchy, nor even to use a cache coherence protocol at all. Instead, these models only specify the behaviors that can be exposed to software. Microarchitectures are free to use any pipeline design, any coherent or non-coherent cache hierarchy, any on-chip interconnect, etc., as long as the design only admits executions that satisfy the memory model rules. That said, to help people understand the actual implementations of the memory model, in this section we provide some guidelines on how architects and programmers should interpret the models' rules.
Both RVWMO and RVTSO are multi-copy atomic (or other-multi-copy-atomic): any store value that is visible to a hart other than the one that originally issued it must also be conceptually visible to all other harts in the system. In other words, harts may forward from their own previous stores before those stores have become globally visible to all harts, but no early inter-hart forwarding is permitted. Multi-copy atomicity may be enforced in a number of ways. It might hold inherently due to the physical design of the caches and store buffers, it may be enforced via a single-writer/multiple-reader cache coherence protocol, or it might hold due to some other mechanism.
Although multi-copy atomicity does impose some restrictions on the microarchitecture, it is one of the key properties keeping the memory model from becoming extremely complicated. For example, a hart may not legally forward a value from a neighbor hart’s private store buffer (unless of course it is done in such a way that no new illegal behaviors become architecturally visible). Nor may a cache coherence protocol forward a value from one hart to another until the coherence protocol has invalidated all older copies from other caches. Of course, microarchitectures may (and high-performance implementations likely will) violate these rules under the covers through speculation or other optimizations, as long as any non-compliant behaviors are not exposed to the programmer.
As a rough guideline for interpreting the PPO rules in RVWMO, we expect the following from the software perspective:
- programmers will use PPO rules 1 and 4-8 regularly and actively.
- expert programmers will use PPO rules 9-11 to speed up critical paths of important data structures.
- even expert programmers will rarely if ever use PPO rules 2-3 and 12-13 directly. These are included to facilitate common microarchitectural optimizations (rule 2) and the operational formal modeling approach (rules 3 and 12-13) described in Section B.2.3. They also facilitate the process of porting code from other architectures that have similar rules.
We also expect the following from the hardware perspective:
- PPO rules 1 and 3-6 reflect well-understood rules that should pose few surprises to architects.
- PPO rule 2 reflects a natural and common hardware optimization, but one that is very subtle and hence is worth double checking carefully.
- PPO rule 7 may not be immediately obvious to architects, but it is a standard memory model requirement
- The load value axiom, the atomicity axiom, and PPO rules
8-13 reflect rules that most
hardware implementations will enforce naturally, unless they contain
extreme optimizations. Of course, implementations should make sure to
double check these rules nevertheless. Hardware must also ensure that
syntactic dependencies are not
optimized away.
Architectures are free to implement any of the memory model rules as conservatively as they choose. For example, a hardware implementation may choose to do any or all of the following:
- interpret all fences as if they were FENCE RW,RW (or FENCE IORW,IORW, if I/O is involved), regardless of the bits actually set
- implement all fences with PW and SR as if they were FENCE RW,RW (or FENCE IORW,IORW, if I/O is involved), as PW with SR is the most expensive of the four possible main memory ordering components anyway
- emulate aq and rl as described in Section B.1.5
- enforcing all same-address load-load ordering, even in the presence of
patterns such as
fri-rfiandRSW - forbid any forwarding of a value from a store in the store buffer to a subsequent AMO or LR to the same address
- forbid any forwarding of a value from an AMO or SC in the store buffer to a subsequent load to the same address
- implement TSO on all memory accesses, and ignore any main memory fences that do not include PW and SR ordering (e.g., as Ztso implementations will do)
- implement all atomics to be RCsc or even fully ordered, regardless of annotation
Architectures that implement RVTSO can safely do the following:
- Ignore all fences that do not have both PW and SR (unless the fence also orders I/O)
- Ignore all PPO rules except for rules 4 through 7, since the rest are redundant with other PPO rules under RVTSO assumptions
Other general notes:
- Silent stores (i.e., stores that write the same value that already exists at a memory location) behave like any other store from a memory model point of view. Likewise, even when an AMO does not change the value in memory (e.g., an AMOMAX when the current memory value ≥ rs2), it is still semantically considered a store operation. Microarchitectures that attempt to implement silent stores must take care to ensure that the memory model is still obeyed, particularly in cases such as RSW Section B.1.3.5 which tend to be incompatible with silent stores.
- Writes may be merged (i.e., two consecutive writes to the same address may be merged) or subsumed (i.e., the earlier of two back-to-back writes to the same address may be elided) as long as the resulting behavior does not otherwise violate the memory model semantics.
The question of write subsumption can be understood from the following example:
Table 84. Write subsumption litmus test, allowed execution
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 3 | li t3, 2 | ||
| li t2, 1 | |||
| (a) | sw t1,0(s0) | (d) | lw a0,0(s1) |
| (b) | fence w, w | (e) | sw a0,0(s0) |
| (c) | sw t2,0(s1) | (f) | sw t3,0(s0) |
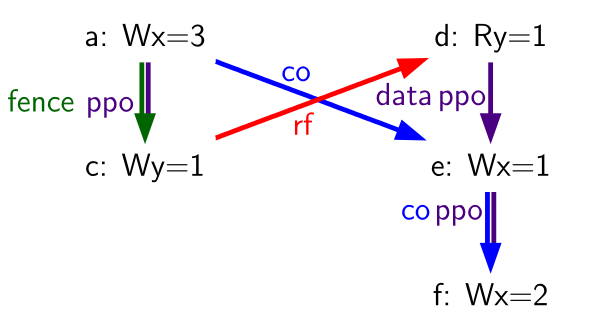
As written, if the load (d) reads value 1, then (a) must precede (f) in the global memory order:
- (a) precedes (c) in the global memory order because of rule 4
- (c) precedes (d) in the global memory order because of the Load Value axiom
- (d) precedes (e) in the global memory order because of rule 10
- (e) precedes (f) in the global memory order because of rule 1
In other words the final value of the memory location whose address is
in s0 must be 2 (the value written by the store (f)) and
cannot be 3 (the value written by the store (a)).
A very aggressive microarchitecture might erroneously decide to discard (e), as (f) supersedes it, and this may in turn lead the microarchitecture to break the now-eliminated dependency between (d) and (f) (and hence also between (a) and (f)). This would violate the memory model rules, and hence it is forbidden. Write subsumption may in other cases be legal, if for example there were no data dependency between (d) and (e).
B.1.6.1 Possible Future Extensions
We expect that any or all of the following possible future extensions would be compatible with the RVWMO memory model:
Vvector ISA extensionsJJIT extension- Native encodings for load and store opcodes with aq and rl set
- Fences limited to certain addresses
- Cache write-back/flush/invalidate/etc.instructions
B.1.7 Known Issues
B.1.7.1 Mixed-size RSW
Table 85. Mixed-size discrepancy (permitted by axiomatic models, forbidden by operational model)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | li t1, 1 | ||
| (a) | lw a0,0(s0) | (d) | lw a1,0(s1) |
| (b) | fence rw,rw | (e) | amoswap.w.rl a2,t1,0(s2) |
| (c) | sw t1,0(s1) | (f) | ld a3,0(s2) |
| (g) | lw a4,4(s2) | ||
| xor a5,a4,a4 | |||
| add s0,s0,a5 | |||
| (h) | sw t1,0(s0) | ||
Outcome: a0=1, a1=1, a2=0, a3=1, a4=0 | |||
Table 86. Mixed-size discrepancy (permitted by axiomatic models, forbidden by operational model)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | li t1, 1 | ||
| (a) | lw a0,0(s0) | (d) | ld a1,0(s1) |
| (b) | fence rw,rw | (e) | lw a2,4(s1) |
| (c) | sw t1,0(s1) | xor a3,a2,a2 | |
| add s0,s0,a3 | |||
| (f) | sw t1,0(s0) | ||
Outcome: a0=1, a1=1, a2=0 | |||
Table 87. Mixed-size discrepancy (permitted by axiomatic models, forbidden by operational model)
| Hart 0 | Hart 1 | ||
|---|---|---|---|
| li t1, 1 | li t1, 1 | ||
| (a) | lw a0,0(s0) | (d) | sw t1,4(s1) |
| (b) | fence rw,rw | (e) | ld a1,0(s1) |
| (c) | sw t1,0(s1) | (f) | lw a2,4(s1) |
| xor a3,a2,a2 | |||
| add s0,s0,a3 | |||
| (g) | sw t1,0(s0) | ||
Outcome: a0=1, a1=0x100000001, a2=1 | |||
There is a known discrepancy between the operational and axiomatic
specifications within the family of mixed-size RSW variants shown in
Table 85-Table 87.
To address this, we may choose to add something like the following new
PPO rule: Memory operation a precedes memory operation
b in preserved program order (and hence also in the global
memory order) if a precedes b in program
order, a and b both access regular main
memory (rather than I/O regions), a is a load,
b is a store, there is a load m between
a and b, there is a byte x
that both a and m read, there is no store
between a and m that writes to
x, and m precedes b in PPO. In
other words, in herd syntax, we may choose to add
(po-loc & rsw);ppo;[W] to PPO. Many implementations will already
enforce this ordering naturally. As such, even though this rule is not
official, we recommend that implementers enforce it nevertheless in
order to ensure forwards compatibility with the possible future addition
of this rule to RVWMO.
B.2 Formal Memory Model Specifications, Version 0.1
To facilitate formal analysis of RVWMO, this chapter presents a set of formalizations using different tools and modeling approaches. Any discrepancies are unintended; the expectation is that the models describe exactly the same sets of legal behaviors.
This appendix should be treated as commentary; all normative material is provided in Section 3.1 and in the rest of the main body of the ISA specification. All currently known discrepancies are listed in Section B.1.7. Any other discrepancies are unintentional.
B.2.1 Formal Axiomatic Specification in Alloy
We present a formal specification of the RVWMO memory model in Alloy (http://alloy.mit.edu). This model is available online at https://github.com/daniellustig/riscv-memory-model.
The online material also contains some litmus tests and some examples of how Alloy can be used to model check some of the mappings in Section B.1.5.
// =RVWMO PPO=
// Preserved Program Order
fun ppo : Event->Event {
// same-address ordering
po_loc :> Store
+ rdw
+ (AMO + StoreConditional) \<: rfi
// explicit synchronization
+ ppo_fence
+ Acquire \<: ^po :> MemoryEvent
+ MemoryEvent \<: ^po :> Release
+ RCsc \<: ^po :> RCsc
+ pair
// syntactic dependencies
+ addrdep
+ datadep
+ ctrldep :> Store
// pipeline dependencies
+ (addrdep+datadep).rfi
+ addrdep.^po :> Store
}
// the global memory order respects preserved program order
fact { ppo in ^gmo }
// =RVWMO axioms=
// Load Value Axiom
fun candidates[r: MemoryEvent] : set MemoryEvent {
(r.~^gmo & Store & same_addr[r]) // writes preceding r in gmo
+ (r.^~po & Store & same_addr[r]) // writes preceding r in po
}
fun latest_among[s: set Event] : Event { s - s.~^gmo }
pred LoadValue {
all w: Store | all r: Load |
w->r in rf \<=> w = latest_among[candidates[r]]
}
// Atomicity Axiom
pred Atomicity {
all r: Store.~pair | // starting from the lr,
no x: Store & same_addr[r] | // there is no store x to the same addr
x not in same_hart[r] // such that x is from a different hart,
and x in r.~rf.^gmo // x follows (the store r reads from) in gmo,
and r.pair in x.^gmo // and r follows x in gmo
}
// Progress Axiom implicit: Alloy only considers finite executions
pred RISCV_mm { LoadValue and Atomicity /* and Progress */ }
//Basic model of memory
sig Hart { // hardware thread
start : one Event
}
sig Address {}
abstract sig Event {
po: lone Event // program order
}
abstract sig MemoryEvent extends Event {
address: one Address,
acquireRCpc: lone MemoryEvent,
acquireRCsc: lone MemoryEvent,
releaseRCpc: lone MemoryEvent,
releaseRCsc: lone MemoryEvent,
addrdep: set MemoryEvent,
ctrldep: set Event,
datadep: set MemoryEvent,
gmo: set MemoryEvent, // global memory order
rf: set MemoryEvent
}
sig LoadNormal extends MemoryEvent {} // l{b|h|w|d}
sig LoadReserve extends MemoryEvent { // lr
pair: lone StoreConditional
}
sig StoreNormal extends MemoryEvent {} // s{b|h|w|d}
// all StoreConditionals in the model are assumed to be successful
sig StoreConditional extends MemoryEvent {} // sc
sig AMO extends MemoryEvent {} // amo
sig NOP extends Event {}
fun Load : Event { LoadNormal + LoadReserve + AMO }
fun Store : Event { StoreNormal + StoreConditional + AMO }
sig Fence extends Event {
pr: lone Fence, // opcode bit
pw: lone Fence, // opcode bit
sr: lone Fence, // opcode bit
sw: lone Fence // opcode bit
}
sig FenceTSO extends Fence {}
/* Alloy encoding detail: opcode bits are either set (encoded, e.g.,
* as f.pr in iden) or unset (f.pr not in iden). The bits cannot be used for
* anything else */
fact { pr + pw + sr + sw in iden }
// likewise for ordering annotations
fact { acquireRCpc + acquireRCsc + releaseRCpc + releaseRCsc in iden }
// don't try to encode FenceTSO via pr/pw/sr/sw; just use it as-is
fact { no FenceTSO.(pr + pw + sr + sw) }
// =Basic model rules=
// Ordering annotation groups
fun Acquire : MemoryEvent { MemoryEvent.acquireRCpc + MemoryEvent.acquireRCsc }
fun Release : MemoryEvent { MemoryEvent.releaseRCpc + MemoryEvent.releaseRCsc }
fun RCpc : MemoryEvent { MemoryEvent.acquireRCpc + MemoryEvent.releaseRCpc }
fun RCsc : MemoryEvent { MemoryEvent.acquireRCsc + MemoryEvent.releaseRCsc }
// There is no such thing as store-acquire or load-release, unless it's both
fact { Load & Release in Acquire }
fact { Store & Acquire in Release }
// FENCE PPO
fun FencePRSR : Fence { Fence.(pr & sr) }
fun FencePRSW : Fence { Fence.(pr & sw) }
fun FencePWSR : Fence { Fence.(pw & sr) }
fun FencePWSW : Fence { Fence.(pw & sw) }
fun ppo_fence : MemoryEvent->MemoryEvent {
(Load \<: ^po :> FencePRSR).(^po :> Load)
+ (Load \<: ^po :> FencePRSW).(^po :> Store)
+ (Store \<: ^po :> FencePWSR).(^po :> Load)
+ (Store \<: ^po :> FencePWSW).(^po :> Store)
+ (Load \<: ^po :> FenceTSO) .(^po :> MemoryEvent)
+ (Store \<: ^po :> FenceTSO) .(^po :> Store)
}
// auxiliary definitions
fun po_loc : Event->Event { ^po & address.~address }
fun same_hart[e: Event] : set Event { e + e.^~po + e.^po }
fun same_addr[e: Event] : set Event { e.address.~address }
// initial stores
fun NonInit : set Event { Hart.start.*po }
fun Init : set Event { Event - NonInit }
fact { Init in StoreNormal }
fact { Init->(MemoryEvent & NonInit) in ^gmo }
fact { all e: NonInit | one e.*~po.~start } // each event is in exactly one hart
fact { all a: Address | one Init & a.~address } // one init store per address
fact { no Init \<: po and no po :> Init }
// po
fact { acyclic[po] }
// gmo
fact { total[^gmo, MemoryEvent] } // gmo is a total order over all MemoryEvents
//rf
fact { rf.~rf in iden } // each read returns the value of only one write
fact { rf in Store \<: address.~address :> Load }
fun rfi : MemoryEvent->MemoryEvent { rf & (*po + *~po) }
//dep
fact { no StoreNormal \<: (addrdep + ctrldep + datadep) }
fact { addrdep + ctrldep + datadep + pair in ^po }
fact { datadep in datadep :> Store }
fact { ctrldep.*po in ctrldep }
fact { no pair & (^po :> (LoadReserve + StoreConditional)).^po }
fact { StoreConditional in LoadReserve.pair } // assume all SCs succeed
// rdw
fun rdw : Event->Event {
(Load \<: po_loc :> Load) // start with all same_address load-load pairs,
- (~rf.rf) // subtract pairs that read from the same store,
- (po_loc.rfi) // and subtract out "fri-rfi" patterns
}
// filter out redundant instances and/or visualizations
fact { no gmo & gmo.gmo } // keep the visualization uncluttered
fact { all a: Address | some a.~address }
// =Optional: opcode encoding restrictions=
// the list of blessed fences
fact { Fence in
Fence.pr.sr
+ Fence.pw.sw
+ Fence.pr.pw.sw
+ Fence.pr.sr.sw
+ FenceTSO
+ Fence.pr.pw.sr.sw
}
pred restrict_to_current_encodings {
no (LoadNormal + StoreNormal) & (Acquire + Release)
}
// =Alloy shortcuts=
pred acyclic[rel: Event->Event] { no iden & ^rel }
pred total[rel: Event->Event, bag: Event] {
all disj e, f: bag | e->f in rel + ~rel
acyclic[rel]
}
B.2.2 Formal Axiomatic Specification in Herd
The tool herd takes a memory model and a litmus test as
input and simulates the execution of the test on top of the memory
model. Memory models are written in the domain specific language Cat.
This section provides two Cat memory model of RVWMO. The first model,
riscv.cat, a herd version of the RVWMO memory model (2/3), follows the global memory order,
Section 3.1, definition of RVWMO, as much
as is possible for a Cat model. The second model,
riscv.cat, an alternative herd presentation of the RVWMO memory model (3/3), is an equivalent, more efficient,
partial order based RVWMO model.
The simulator herd is part of the diy tool
suite — see http://diy.inria.fr for software and documentation. The
models and more are available online at http://diy.inria.fr/cats7/riscv/.
(*************)
(* Utilities *)
(*************)
(* All fence relations *)
let fence.r.r = [R];fencerel(Fence.r.r);[R]
let fence.r.w = [R];fencerel(Fence.r.w);[W]
let fence.r.rw = [R];fencerel(Fence.r.rw);[M]
let fence.w.r = [W];fencerel(Fence.w.r);[R]
let fence.w.w = [W];fencerel(Fence.w.w);[W]
let fence.w.rw = [W];fencerel(Fence.w.rw);[M]
let fence.rw.r = [M];fencerel(Fence.rw.r);[R]
let fence.rw.w = [M];fencerel(Fence.rw.w);[W]
let fence.rw.rw = [M];fencerel(Fence.rw.rw);[M]
let fence.tso =
let f = fencerel(Fence.tso) in
([W];f;[W]) | ([R];f;[M])
let fence =
fence.r.r | fence.r.w | fence.r.rw |
fence.w.r | fence.w.w | fence.w.rw |
fence.rw.r | fence.rw.w | fence.rw.rw |
fence.tso
(* Same address, no W to the same address in-between *)
let po-loc-no-w = po-loc \ (po-loc?;[W];po-loc)
(* Read same write *)
let rsw = rf^-1;rf
(* Acquire, or stronger *)
let AQ = Acq|AcqRel
(* Release or stronger *)
and RL = RelAcqRel
(* All RCsc *)
let RCsc = Acq|Rel|AcqRel
(* Amo events are both R and W, relation rmw relates paired lr/sc *)
let AMO = R & W
let StCond = range(rmw)
(*************)
(* ppo rules *)
(*************)
(* Overlapping-Address Orderings *)
let r1 = [M];po-loc;[W]
and r2 = ([R];po-loc-no-w;[R]) \ rsw
and r3 = [AMO|StCond];rfi;[R]
(* Explicit Synchronization *)
and r4 = fence
and r5 = [AQ];po;[M]
and r6 = [M];po;[RL]
and r7 = [RCsc];po;[RCsc]
and r8 = rmw
(* Syntactic Dependencies *)
and r9 = [M];addr;[M]
and r10 = [M];data;[W]
and r11 = [M];ctrl;[W]
(* Pipeline Dependencies *)
and r12 = [R];(addr|data);[W];rfi;[R]
and r13 = [R];addr;[M];po;[W]
let ppo = r1 | r2 | r3 | r4 | r5 | r6 | r7 | r8 | r9 | r10 | r11 | r12 | r13
Total
(* Notice that herd has defined its own rf relation *)
(* Define ppo *)
include "riscv-defs.cat"
(********************************)
(* Generate global memory order *)
(********************************)
let gmo0 = (* precursor: ie build gmo as an total order that include gmo0 *)
loc & (W\FW) * FW | # Final write after any write to the same location
ppo | # ppo compatible
rfe # includes herd external rf (optimization)
(* Walk over all linear extensions of gmo0 *)
with gmo from linearizations(M\IW,gmo0)
(* Add initial writes upfront -- convenient for computing rfGMO *)
let gmo = gmo | loc & IW * (M\IW)
(**********)
(* Axioms *)
(**********)
(* Compute rf according to the load value axiom, aka rfGMO *)
let WR = loc & ([W];(gmo|po);[R])
let rfGMO = WR \ (loc&([W];gmo);WR)
(* Check equality of herd rf and of rfGMO *)
empty (rf\rfGMO)|(rfGMO\rf) as RfCons
(* Atomicity axiom *)
let infloc = (gmo & loc)^-1
let inflocext = infloc & ext
let winside = (infloc;rmw;inflocext) & (infloc;rf;rmw;inflocext) & [W]
empty winside as Atomic
Partial
(***************)
(* Definitions *)
(***************)
(* Define ppo *)
include "riscv-defs.cat"
(* Compute coherence relation *)
include "cos-opt.cat"
(**********)
(* Axioms *)
(**********)
(* Sc per location *)
acyclic co|rf|fr|po-loc as Coherence
(* Main model axiom *)
acyclic co|rfe|fr|ppo as Model
(* Atomicity axiom *)
empty rmw & (fre;coe) as Atomic
B.2.3 An Operational Memory Model
This is an alternative presentation of the RVWMO memory model in operational style. It aims to admit exactly the same extensional behavior as the axiomatic presentation: for any given program, admitting an execution if and only if the axiomatic presentation allows it.
The axiomatic presentation is defined as a predicate on complete candidate executions. In contrast, this operational presentation has an abstract microarchitectural flavor: it is expressed as a state machine, with states that are an abstract representation of hardware machine states, and with explicit out-of-order and speculative execution (but abstracting from more implementation-specific microarchitectural details such as register renaming, store buffers, cache hierarchies, cache protocols, etc.). As such, it can provide useful intuition. It can also construct executions incrementally, making it possible to interactively and randomly explore the behavior of larger examples, while the axiomatic model requires complete candidate executions over which the axioms can be checked.
The operational presentation covers mixed-size execution, with potentially overlapping memory accesses of different power-of-two byte sizes. Misaligned accesses are broken up into single-byte accesses.
The operational model, together with a fragment of the RISC-V ISA
semantics (RV64I and A), are integrated into the rmem exploration tool
(https://github.com/rems-project/rmem). rmem can explore litmus tests
(see Section B.1.2) and small ELF binaries
exhaustively, pseudorandomly, and interactively. In rmem, the ISA
semantics is expressed explicitly in Sail (see
https://github.com/rems-project/sail for the Sail language, and
https://github.com/rems-project/sail-riscv for the RISC-V ISA model),
and the concurrency semantics is expressed in Lem (see
https://github.com/rems-project/lem for the Lem language).
rmem has a command-line interface and a web-interface. The
web-interface runs entirely on the client side, and is provided online
together with a library of litmus tests:
http://www.cl.cam.ac.uk/. The command-line interface is
faster than the web-interface, specially in exhaustive mode.
Below is an informal introduction of the model states and transitions. The description of the formal model starts in the next subsection.
Terminology: In contrast to the axiomatic presentation, here every
memory operation is either a load or a store. Hence, AMOs give rise to
two distinct memory operations, a load and a store. When used in
conjunction with instruction, the terms load and store refer
to instructions that give rise to such memory operations. As such, both
include AMO instructions. The term acquire refers to an instruction
(or its memory operation) with the acquire-RCpc or acquire-RCsc
annotation. The term release refers to an instruction (or its memory
operation) with the release-RCpc or release-RCsc annotation.
Model states
Model states: A model state consists of a shared memory and a tuple of hart states.

The shared memory state records all the memory store operations that have propagated so far, in the order they propagated (this can be made more efficient, but for simplicity of the presentation we keep it this way).
Each hart state consists principally of a tree of instruction instances, some of which have been finished, and some of which have not. Non-finished instruction instances can be subject to restart, e.g. if they depend on an out-of-order or speculative load that turns out to be unsound.
Conditional branch and indirect jump instructions may have multiple successors in the instruction tree. When such instruction is finished, any untaken alternative paths are discarded.
Each instruction instance in the instruction tree has a state that includes an execution state of the intra-instruction semantics (the ISA pseudocode for this instruction). The model uses a formalization of the intra-instruction semantics in Sail. One can think of the execution state of an instruction as a representation of the pseudocode control state, pseudocode call stack, and local variable values. An instruction instance state also includes information about the instance’s memory and register footprints, its register reads and writes, its memory operations, whether it is finished, etc.
Model transitions
The model defines, for any model state, the set of allowed transitions, each of which is a single atomic step to a new abstract machine state. Execution of a single instruction will typically involve many transitions, and they may be interleaved in operational-model execution with transitions arising from other instructions. Each transition arises from a single instruction instance; it will change the state of that instance, and it may depend on or change the rest of its hart state and the shared memory state, but it does not depend on other hart states, and it will not change them. The transitions are introduced below and defined in Section B.2.3.5, with a precondition and a construction of the post-transition model state for each.
Transitions for all instructions:
- Fetch instruction: This transition represents a fetch and decode of a new instruction instance, as a program order successor of a previously fetched instruction instance (or the initial fetch address).
The model assumes the instruction memory is fixed; it does not describe the behavior of self-modifying code. In particular, the Fetch instruction transition does not generate memory load operations, and the shared memory is not involved in the transition. Instead, the model depends on an external oracle that provides an opcode when given a memory location.
- Register write: This is a write of a register value.
- Register read: This is a read of a register value from the most recent program-order-predecessor instruction instance that writes to that register.
- Pseudocode internal step: This covers pseudocode internal computation: arithmetic, function calls, etc.
- Finish instruction: At this point the instruction pseudocode is done, the instruction cannot be restarted, memory accesses cannot be discarded, and all memory effects have taken place. For conditional branch and indirect jump instructions, any program order successors that were fetched from an address that is not the one that was written to the pc register are discarded, together with the sub-tree of instruction instances below them.
Transitions specific to load instructions:
-
Initiate memory load operations: At this point the memory footprint of the load instruction is provisionally known (it could change if earlier instructions are restarted) and its individual memory load operations can start being satisfied.
-
Satisfy memory load operation by forwarding from unpropagated stores: This partially or entirely satisfies a single memory load operation by forwarding, from program-order-previous memory store operations.
-
Satisfy memory load operation from memory: This entirely satisfies the outstanding slices of a single memory load operation, from memory.
-
Complete load operations: At this point all the memory load operations of the instruction have been entirely satisfied and the instruction pseudocode can continue executing. A load instruction can be subject to being restarted until the transition. But, under some conditions, the model might treat a load instruction as non-restartable even before it is finished (e.g. see ).
Transitions specific to store instructions:
-
Initiate memory store operation footprints: At this point the memory footprint of the store is provisionally known.
-
Instantiate memory store operation values: At this point the memory store operations have their values and program-order-successor memory load operations can be satisfied by forwarding from them.
-
Commit store instruction: At this point the store operations are guaranteed to happen (the instruction can no longer be restarted or discarded), and they can start being propagated to memory.
-
Propagate store operation: This propagates a single memory store operation to memory.
-
Complete store operations: At this point all the memory store operations of the instruction have been propagated to memory, and the instruction pseudocode can continue executing.
Transitions specific to sc instructions:
- Early sc fail: This causes the
scto fail, either a spontaneous fail or because it is not paired with a program-order-previouslr. - Paired sc: This transition indicates the
scis paired with anlrand might succeed. - Commit and propagate store operation of an sc: This is an atomic execution of the transitions Commit store instruction and Propagate store operation, it is enabled
only if the stores from which the
lrread from have not been overwritten. - Late sc fail: This causes the
scto fail, either a spontaneous fail or because the stores from which thelrread from have been overwritten.
Transitions specific to AMO instructions:
- Satisfy, commit and propagate operations of an AMO: This is an atomic execution of all the transitions needed to satisfy the load operation, do the required arithmetic, and propagate the store operation.
Transitions specific to fence instructions:
The transitions labeled ○ can always be taken eagerly, as soon as their precondition is satisfied, without excluding other behavior; the ∙ cannot. Although Fetch instruction is marked with a ∙, it can be taken eagerly as long as it is not taken infinitely many times.
An instance of a non-AMO load instruction, after being fetched, will typically experience the following transitions in this order:
- Register read
- Initiate memory load operations
- Satisfy memory load operation by forwarding from unpropagated stores and/or Satisfy memory load operation from memory (as many as needed to satisfy all the load operations of the instance)
- Complete load operations
- Register write
- Finish instruction
Before, between, and after the transitions above, any number of Pseudocode internal step transitions may appear. In addition, a Fetch instruction transition for fetching the instruction in the next program location will be available until it is taken.
This concludes the informal description of the operational model. The following sections describe the formal operational model.
B.2.3.1 Intra-instruction Pseudocode Execution
The intra-instruction semantics for each instruction instance is expressed as a state machine, essentially running the instruction pseudocode. Given a pseudocode execution state, it computes the next state. Most states identify a pending memory or register operation, requested by the pseudocode, which the memory model has to do. The states are (this is a tagged union; tags in small-caps):
| Load_mem(kind, address, size, load_continuation) | - memory load operation |
| Early_sc_fail(res_continuation) | - allow sc to fail early |
| Store_ea(kind, address, size, next_state) | - memory store effective address |
| Store_memv(mem_value, store_continuation) | - memory store value |
| Fence(kind, next_state) | - fence |
| Read_reg(reg_name, read_continuation) | - register read |
| Write_reg(reg_name, reg_value, next_state) | - register write |
| Internal(next_state) | - pseudocode internal step |
| Done | - end of pseudocode |
Here:
- mem_value and reg_value are lists of bytes;
- address is an integer of XLEN bits;
for load/store, kind identifies whether it is lr/sc,
acquire-RCpc/release-RCpc, acquire-RCsc/release-RCsc,
acquire-release-RCsc;
- for fence, kind identifies whether it is a normal or TSO, and (for normal fences) the predecessor and successor ordering bits;
- reg_name identifies a register and a slice thereof (start and end bit
indices); and the continuations describe how the instruction instance will continue
for each value that might be provided by the surrounding memory model
(the load_continuation and read_continuation take the value loaded
from memory and read from the previous register write, the
store_continuation takes false for an
scthat failed and true in all other cases, and res_continuation takes false if thescfails and true otherwise).
For example, given the load instruction lw x1,0(x2), an execution will
typically go as follows. The initial execution state will be computed
from the pseudocode for the given opcode. This can be expected to be
Read_reg(x2, read_continuation). Feeding the most recently written
value of register x2 (the instruction semantics will be blocked if
necessary until the register value is available), say 0x4000, to
read_continuation returns Load_mem(plain_load, 0x4000, 4,
load_continuation). Feeding the 4-byte value loaded from memory
location 0x4000, say 0x42, to load_continuation returns
Write_reg(x1, 0x42, Done). Many Internal(next_state) states may
appear before and between the states above.
Notice that writing to memory is split into two steps, Store_ea and Store_memv: the first one makes the memory footprint of the store provisionally known, and the second one adds the value to be stored. We ensure these are paired in the pseudocode (Store_ea followed by Store_memv), but there may be other steps between them.
It is observable that the Store_ea can occur before the value to be stored is determined. For example, for the litmus test LB+fence.r.rw+data-po to be allowed by the operational model (as it is by RVWMO), the first store in Hart 1 has to take the Store_ea step before its value is determined, so that the second store can see it is to a non-overlapping memory footprint, allowing the second store to be committed out of order without violating coherence.
The pseudocode of each instruction performs at most one store or one load, except for AMOs that perform exactly one load and one store. Those memory accesses are then split apart into the architecturally atomic units by the hart semantics (see Initiate memory load operations and Initiate memory store operation footprints below).
Informally, each bit of a register read should be satisfied from a register write by the most recent (in program order) instruction instance that can write that bit (or from the hart’s initial register state if there is no such write). Hence, it is essential to know the register write footprint of each instruction instance, which we calculate when the instruction instance is created (see the Fetch instruction action of below). We ensure in the pseudocode that each instruction does at most one register write to each register bit, and also that it does not try to read a register value it just wrote.
Data-flow dependencies (address and data) in the model emerge from the fact that each register read has to wait for the appropriate register write to be executed (as described above).
B.2.3.2 Instruction Instance State
Each instruction instance _i has a state comprising:
- program_loc, the memory address from which the instruction was fetched;
- instruction_kind, identifying whether this is a load, store, AMO,
fence, branch/jump or a
simpleinstruction (this also includes a kind similar to the one described for the pseudocode execution states); - src_regs, the set of source _reg_name_s (including system registers), as statically determined from the pseudocode of the instruction;
- dst_regs, the destination _reg_name_s (including system registers), as statically determined from the pseudocode of the instruction;
- pseudocode_state (or sometimes just
statefor short), one of (this
| Plain(isa_state) | - ready to make a pseudocode transition |
|---|---|
| Pending_mem_loads(load_continuation) | - requesting memory load operation(s) |
| Pending_mem_stores(store_continuation) | - requesting memory store operation(s) |
- reg_reads, the register reads the instance has performed, including, for each one, the register write slices it read from;
- reg_writes, the register writes the instance has performed;
- mem_loads, a set of memory load operations, and for each one the as-yet-unsatisfied slices (the byte indices that have not been satisfied yet), and, for the satisfied slices, the store slices (each consisting of a memory store operation and subset of its byte indices) that satisfied it.
- mem_stores, a set of memory store operations, and for each one a flag that indicates whether it has been propagated (passed to the shared memory) or not.
- information recording whether the instance is committed, finished, etc.
Each memory load operation includes a memory footprint (address and size). Each memory store operations includes a memory footprint, and, when available, a value.
A load instruction instance with a non-empty mem_loads, for which all the load operations are satisfied (i.e. there are no unsatisfied load slices) is said to be entirely satisfied.
Informally, an instruction instance is said to have fully determined
data if the load (and sc) instructions feeding its source registers
are finished. Similarly, it is said to have a fully determined memory
footprint if the load (and sc) instructions feeding its memory
operation address register are finished. Formally, we first define the
notion of fully determined register write: a register write
w from reg_writes of instruction instance
i is said to be fully determined if one of the following
conditions hold:
- i is finished; or
- the value written by w is not affected by a memory
operation that i has made (i.e. a value loaded from memory
or the result of
sc), and, for every register read that i has made, that affects w, the register write from which i read is fully determined (or i read from the initial register state).
Now, an instruction instance i is said to have fully determined data if for every register read r from reg_reads, the register writes that r reads from are fully determined. An instruction instance i is said to have a fully determined memory footprint if for every register read r from reg_reads that feeds into i’s memory operation address, the register writes that r reads from are fully determined.
The rmem tool records, for every register write, the set of register
writes from other instructions that have been read by this instruction
at the point of performing the write. By carefully arranging the
pseudocode of the instructions covered by the tool we were able to make
it so that this is exactly the set of register writes on which the write
depends on.
B.2.3.3 Hart State
The model state of a single hart comprises:
- hart_id, a unique identifier of the hart;
- initial_register_state, the initial register value for each register;
- initial_fetch_address, the initial instruction fetch address;
- instruction_tree, a tree of the instruction instances that have been fetched (and not discarded), in program order.
B.2.3.4 Shared Memory State
The model state of the shared memory comprises a list of memory store operations, in the order they propagated to the shared memory.
When a store operation is propagated to the shared memory it is simply added to the end of the list. When a load operation is satisfied from memory, for each byte of the load operation, the most recent corresponding store slice is returned.
For most purposes, it is simpler to think of the shared memory as an
array, i.e., a map from memory locations to memory store operation
slices, where each memory location is mapped to a one-byte slice of the
most recent memory store operation to that location. However, this
abstraction is not detailed enough to properly handle the sc
instruction. The RVWMO allows store operations from the same hart as the
sc to intervene between the store operation of the sc and the store
operations the paired lr read from. To allow such store operations to
intervene, and forbid others, the array abstraction must be extended to
record more information. Here, we use a list as it is very simple, but a
more efficient and scalable implementations should probably use
something better.
B.2.3.5 Transitions
Each of the paragraphs below describes a single kind of system transition. The description starts with a condition over the current system state. The transition can be taken in the current state only if the condition is satisfied. The condition is followed by an action that is applied to that state when the transition is taken, in order to generate the new system state.
B.2.3.5.1 Fetch instruction
A possible program-order-successor of instruction instance i can be fetched from address loc if:
- it has not already been fetched, i.e., none of the immediate successors of i in the hart’s instruction_tree are from loc; and
- if i’s pseudocode has already written an address to pc, then loc must be that address, otherwise loc is:
- for a conditional branch, the successor address or the branch target address;
- for a (direct) jump and link instruction (
jal), the target address; - for an indirect jump instruction (
jalr), any address; and - for any other instruction, i.program_loc+4.
Action: construct a freshly initialized instruction instance i' for the instruction in the program memory at loc, with state Plain(isa_state), computed from the instruction pseudocode, including the static information available from the pseudocode such as its instruction_kind, src_regs, and dst_regs, and add i' to the hart’s instruction_tree as a successor of i.
The possible next fetch addresses (loc) are available immediately
after fetching i and the model does not need to wait for
the pseudocode to write to pc; this allows out-of-order execution, and
speculation past conditional branches and jumps. For most instructions
these addresses are easily obtained from the instruction pseudocode. The
only exception to that is the indirect jump instruction (jalr), where
the address depends on the value held in a register. In principle the
mathematical model should allow speculation to arbitrary addresses here.
The exhaustive search in the rmem tool handles this by running the
exhaustive search multiple times with a growing set of possible next
fetch addresses for each indirect jump. The initial search uses empty
sets, hence there is no fetch after indirect jump instruction until the
pseudocode of the instruction writes to pc, and then we use that value
for fetching the next instruction. Before starting the next iteration of
exhaustive search, we collect for each indirect jump (grouped by code
location) the set of values it wrote to pc in all the executions in
the previous search iteration, and use that as possible next fetch
addresses of the instruction. This process terminates when no new fetch
addresses are detected.
B.2.3.5.2 Initiate memory load operations
An instruction instance i in state Plain(Load_mem(kind, address, size, load_continuation)) can always initiate the corresponding memory load operations. Action:
- Construct the appropriate memory load operations mlos:
- if address is aligned to size then mlos is a single memory load operation of size bytes from address;
- otherwise, mlos is a set of size memory load operations, each of one byte, from the addresses address…address+size−1.
- set mem_loads of i to mlos; and
- update the state of i to Pending_mem_loads(load_continuation).
In Section 3.1.1.1 it is said that misaligned memory accesses may be decomposed at any granularity. Here we decompose them to one-byte accesses as this granularity subsumes all others.
B.2.3.5.3 Satisfy memory load operation by forwarding from unpropagated stores
For a non-AMO load instruction instance i in state Pending_mem_loads(load_continuation), and a memory load operation mlo in i.mem_loads that has unsatisfied slices, the memory load operation can be partially or entirely satisfied by forwarding from unpropagated memory store operations by store instruction instances that are program-order-before i if:
- all program-order-previous
fenceinstructions with.srand.pwset are finished; - for every program-order-previous
fenceinstruction, f, with.srand.prset, and.pwnot set, if f is not finished then all load instructions that are program-order-before f are entirely satisfied; - for every program-order-previous
fence.tsoinstruction, f, that is not finished, all load instructions that are program-order-before f are entirely satisfied; - if i is a load-acquire-RCsc, all program-order-previous store-releases-RCsc are finished;
- if i is a load-acquire-release, all program-order-previous instructions are finished;
- all non-finished program-order-previous load-acquire instructions are entirely satisfied; and
- all program-order-previous store-acquire-release instructions are finished;
Let msoss be the set of all unpropagated memory store
operation slices from non-sc store instruction instances that are
program-order-before i and have already calculated the
value to be stored, that overlap with the unsatisfied slices of
mlo, and which are not superseded by intervening store
operations or store operations that are read from by an intervening
load. The last condition requires, for each memory store operation slice
msos in msoss from instruction
i':
- that there is no store instruction program-order-between i and i' with a memory store operation overlapping msos; and
- that there is no load instruction program-order-between i and i' that was satisfied from an overlapping memory store operation slice from a different hart.
Action:
- update i.mem_loads to indicate that mlo was satisfied by msoss; and
- restart any speculative instructions which have violated coherence as a result of this, i.e., for every non-finished instruction i' that is a program-order-successor of i, and every memory load operation mlo' of i' that was satisfied from msoss', if there exists a memory store operation slice msos' in msoss', and an overlapping memory store operation slice from a different memory store operation in msoss, and msos' is not from an instruction that is a program-order-successor of i, restart i' and its restart-dependents.
Where, the restart-dependents of instruction j are:
- program-order-successors of j that have data-flow dependency on a register write of j;
- program-order-successors of j that have a memory load operation that reads from a memory store operation of j (by forwarding);
- if j is a load-acquire, all the program-order-successors of j;
- if j is a load, for every
fence, f, with.srand.prset, and.pwnot set, that is a program-order-successor of j, all the load instructions that are program-order-successors of f; - if j is a load, for every
fence.tso, f, that is a program-order-successor of j, all the load instructions that are program-order-successors of f; and - (recursively) all the restart-dependents of all the instruction instances above.
Forwarding memory store operations to a memory load might satisfy only some slices of the load, leaving other slices unsatisfied.
A program-order-previous store operation that was not available when taking the transition above might make msoss provisionally unsound (violating coherence) when it becomes available. That store will prevent the load from being finished (see Finish instruction), and will cause it to restart when that store operation is propagated (see Propagate store operation).
A consequence of the transition condition above is that store-release-RCsc memory store operations cannot be forwarded to load-acquire-RCsc instructions: msoss does not include memory store operations from finished stores (as those must be propagated memory store operations), and the condition above requires all program-order-previous store-releases-RCsc to be finished when the load is acquire-RCsc.
B.2.3.5.4 Satisfy memory load operation from memory
For an instruction instance i of a non-AMO load instruction or an AMO instruction in the context of the Satisfy, commit and propagate operations of an AMO transition, any memory load operation mlo in i.mem_loads that has unsatisfied slices, can be satisfied from memory if all the conditions of <sat_by_forwarding, Satisfy memory load operation by forwarding from unpropagated stores>> are satisfied. Action: let msoss be the memory store operation slices from memory covering the unsatisfied slices of mlo, and apply the action of Satisfy memory operation by forwarding from unpropagates stores.
Note that Satisfy memory operation by forwarding from unpropagates stores might leave some slices of the memory load operation unsatisfied, those will have to be satisfied by taking the transition again, or taking Satisfy memory load operation from memory. Satisfy memory load operation from memory, on the other hand, will always satisfy all the unsatisfied slices of the memory load operation.
B.2.3.5.5 Complete load operations
A load instruction instance i in state Pending_mem_loads(load_continuation) can be completed (not to be confused with finished) if all the memory load operations i.mem_loads are entirely satisfied (i.e. there are no unsatisfied slices). Action: update the state of i to Plain(load_continuation(mem_value)), where mem_value is assembled from all the memory store operation slices that satisfied i.mem_loads.
B.2.3.5.6 Early sc fail
An sc instruction instance i in state
Plain(Early_sc_fail(res_continuation)) can always be made to fail.
Action: update the state of i to
Plain(res_continuation(false)).
B.2.3.5.7 Paired sc
An sc instruction instance i in state
Plain(Early_sc_fail(res_continuation)) can continue its (potentially
successful) execution if i is paired with an lr. Action:
update the state of i to Plain(res_continuation(true)).
B.2.3.5.8 Initiate memory store operation footprints
An instruction instance i in state Plain(Store_ea(kind, address, size, next_state)) can always announce its pending memory store operation footprint. Action:
- construct the appropriate memory store operations msos (without the store value):
- if address is aligned to size then msos is a single memory store operation of size bytes to address;
- otherwise, msos is a set of size memory store operations, each of one-byte size, to the addresses address…address+size−1.
- set i.mem_stores to msos; and
- update the state of i to Plain(next_state).
Note that after taking the transition above the memory store operations do not yet have their values. The importance of splitting this transition from the transition below is that it allows other program-order-successor store instructions to observe the memory footprint of this instruction, and if they don’t overlap, propagate out of order as early as possible (i.e. before the data register value becomes available).
B.2.3.5.9 Instantiate memory store operation values
An instruction instance i in state Plain(Store_memv(mem_value, store_continuation)) can always instantiate the values of the memory store operations i.mem_stores. Action:
- split mem_value between the memory store operations i.mem_stores; and
- update the state of i to Pending_mem_stores(store_continuation).
B.2.3.5.10 Commit store instruction
An uncommitted instruction instance i of a non-sc store
instruction or an sc instruction in the context of the Commit and propagate store operation of an sc
transition, in state Pending_mem_stores(store_continuation), can be
committed (not to be confused with propagated) if:
- i has fully determined data;
- all program-order-previous conditional branch and indirect jump instructions are finished;
- all program-order-previous
fenceinstructions with.swset are finished; - all program-order-previous
fence.tsoinstructions are finished; - all program-order-previous load-acquire instructions are finished;
- all program-order-previous store-acquire-release instructions are finished;
- if i is a store-release, all program-order-previous instructions are finished;
- all program-order-previous memory access instructions have a fully determined memory footprint;
- all program-order-previous store instructions, except for
scthat failed, have initiated and so have non-empty mem_stores; and - all program-order-previous load instructions have initiated and so have non-empty mem_loads.
Action: record that i is committed.
Notice that if condition 8 is satisfied the conditions 9 and 10 are also satisfied, or will be satisfied after taking some eager transitions. Hence, requiring them does not strengthen the model. By requiring them, we guarantee that previous memory access instructions have taken enough transitions to make their memory operations visible for the condition check of , which is the next transition the instruction will take, making that condition simpler.
B.2.3.5.11 Propagate store operation
For a committed instruction instance i in state Pending_mem_stores(store_continuation), and an unpropagated memory store operation mso in i.mem_stores, mso can be propagated if:
- all memory store operations of program-order-previous store instructions that overlap with mso have already propagated;
- all memory load operations of program-order-previous load instructions that overlap with mso have already been satisfied, and (the load instructions) are non-restartable (see definition below); and
- all memory load operations that were satisfied by forwarding mso are entirely satisfied.
Where a non-finished instruction instance j is non-restartable if:
- there does not exist a store instruction s and an unpropagated memory store operation mso of s such that applying the action of the Propagate store operation transition to mso will result in the restart of j; and
- there does not exist a non-finished load instruction l and a memory load operation mlo of l such that applying the action of the Satisfy memory load operation by forwarding from unpropagated stores/Satisfy memory load operation from memory transition (even if mlo is already satisfied) to mlo will result in the restart of j.
Action:
- update the shared memory state with mso;
- update i.mem_stores to indicate that mso was propagated; and
- restart any speculative instructions which have violated coherence as a result of this, i.e., for every non-finished instruction i' program-order-after i and every memory load operation mlo' of i' that was satisfied from msoss', if there exists a memory store operation slice msos' in msoss' that overlaps with mso and is not from mso, and msos' is not from a program-order-successor of i, restart i' and its restart-dependents (see Satisfy memory load operation by forwarding from unpropagated stores).
B.2.3.5.12 Commit and propagate store operation of an sc
An uncommitted sc instruction instance i, from hart
h, in state Pending_mem_stores(store_continuation), with
a paired lr i' that has been satisfied by some store
slices msoss, can be committed and propagated at the same
time if:
- i' is finished;
- every memory store operation that has been forwarded to i' is propagated;
- the conditions of Commit store instruction is satisfied;
- the conditions of Propagate store instruction is satisfied (notice that an
scinstruction can only have one memory store operation); and - for every store slice msos from msoss, msos has not been overwritten, in the shared memory, by a store that is from a hart that is not h, at any point since msos was propagated to memory.
Action:
- apply the actions of Commit store instruction; and
- apply the action of Propagate store instruction.
B.2.3.5.13 Late sc fail
An sc instruction instance i in state
Pending_mem_stores(store_continuation), that has not propagated its
memory store operation, can always be made to fail. Action:
- clear i.mem_stores; and
- update the state of i to Plain(store_continuation(false)).
For efficiency, the rmem tool allows this transition only when it is
not possible to take the Commit and propagate store operation of an sc transition. This does not affect the set of
allowed final states, but when explored interactively, if the sc
should fail one should use the Early sc fail transition instead of waiting for this transition.
B.2.3.5.14 Complete store operations
A store instruction instance i in state Pending_mem_stores(store_continuation), for which all the memory store operations in i.mem_stores have been propagated, can always be completed (not to be confused with finished). Action: update the state of i to Plain(store_continuation(true)).
B.2.3.5.15 Satisfy, commit and propagate operations of an AMO
An AMO instruction instance i in state Pending_mem_loads(load_continuation) can perform its memory access if it is possible to perform the following sequence of transitions with no intervening transitions:
- Satisfy memory load operation from memory
- Complete load operations
- Pseudocode internal step (zero or more times)
- Instantiate memory store operation values
- Commit store instruction
- Propagate store operation
- Complete store operations
and in addition, the condition of Finish instruction, with the exception of not requiring i to be in state Plain(Done), holds after those transitions. Action: perform the above sequence of transitions (this does not include Finish instruction), one after the other, with no intervening transitions.
Notice that program-order-previous stores cannot be forwarded to the load of an AMO. This is simply because the sequence of transitions above does not include the forwarding transition. But even if it did include it, the sequence will fail when trying to do the Propagate store operation transition, as this transition requires all program-order-previous store operations to overlapping memory footprints to be propagated, and forwarding requires the store operation to be unpropagated.
In addition, the store of an AMO cannot be forwarded to a program-order-successor load. Before taking the transition above, the store operation of the AMO does not have its value and therefore cannot be forwarded; after taking the transition above the store operation is propagated and therefore cannot be forwarded.
B.2.3.5.16 Commit fence
A fence instruction instance i in state Plain(Fence(kind, next_state)) can be committed if:
- if i is a normal fence and it has
.prset, all program-order-previous load instructions are finished; - if i is a normal fence and it has
.pwset, all program-order-previous store instructions are finished; and - if i is a
fence.tso, all program-order-previous load and store instructions are finished.
Action:
- record that i is committed; and
- update the state of i to Plain(next_state).
B.2.3.5.17 Register read
An instruction instance i in state Plain(Read_reg(reg_name, read_cont)) can do a register read of reg_name if every instruction instance that it needs to read from has already performed the expected reg_name register write.
Let read_sources include, for each bit of reg_name, the write to that bit by the most recent (in program order) instruction instance that can write to that bit, if any. If there is no such instruction, the source is the initial register value from initial_register_state. Let reg_value be the value assembled from read_sources. Action:
- add reg_name to i.reg_reads with read_sources and reg_value; and
- update the state of i to Plain(read_cont(reg_value)).
B.2.3.5.18 Register write
An instruction instance i in state Plain(Write_reg(reg_name, reg_value, next_state)) can always do a reg_name register write. Action:
- add reg_name to i.reg_writes with deps and reg_value; and
- update the state of i to Plain(next_state).
where deps is a pair of the set of all read_sources from i.reg_reads, and a flag that is true iff i is a load instruction instance that has already been entirely satisfied.
B.2.3.5.19 Pseudocode internal step
An instruction instance i in state Plain(Internal(next_state)) can always do that pseudocode-internal step. Action: update the state of i to Plain(next_state).
B.2.3.5.20 Finish instruction
A non-finished instruction instance i in state Plain(Done) can be finished if:
-
if i is a load instruction:
-
all program-order-previous load-acquire instructions are finished;
-
all program-order-previous
fenceinstructions with.srset are finished; -
for every program-order-previous
fence.tsoinstruction, f, that is not finished, all load instructions that are program-order-before f are finished; and -
it is guaranteed that the values read by the memory load operations of i will not cause coherence violations, i.e., for any program-order-previous instruction instance i', let cfp be the combined footprint of propagated memory store operations from store instructions program-order-between i and i', and fixed memory store operations that were forwarded to i from store instructions program-order-between i and i' including i', and let /cfp be the complement of cfp in the memory footprint of i. If /cfp is not empty:
-
i' has a fully determined memory footprint;
-
i' has no unpropagated memory store operations that overlap with /cfp; and
-
if i' is a load with a memory footprint that overlaps with /cfp, then all the memory load operations of i' that overlap with /cfp are satisfied and i' is non-restartable (see the Propagate store operation transition for how to determined if an instruction is non-restartable). Here, a memory store operation is called fixed if the store instruction has fully determined data.
-
i has a fully determined data; and
-
if i is not a fence, all program-order-previous conditional branch and indirect jump instructions are finished.
Action:
- if i is a conditional branch or indirect jump instruction, discard any untaken paths of execution, i.e., remove all instruction instances that are not reachable by the branch/jump taken in instruction_tree; and
- record the instruction as finished, i.e., set finished to true.
B.2.3.6 Limitations
- The model covers user-level RV64IA. In particular, it does
not support the misaligned atomicity granule PMA or the total store
ordering extension
Ztso. It should be trivial to adapt the model to RV32IA and to theG,QandCextensions, but we have never tried it. This will involve, mostly, writing Sail code for the instructions, with minimal, if any, changes to the concurrency model. - The model covers only normal memory accesses (it does not handle I/O accesses).
- The model does not cover TLB-related effects.
- The model assumes the instruction memory is fixed. In particular, the Fetch instruction transition does not generate memory load operations, and the shared memory is not involved in the transition. Instead, the model depends on an external oracle that provides an opcode when given a memory location.
- The model does not cover exceptions, traps and interrupts.